Anthony Scopatz, Assistant Professor at the University of South Carolina, HDF guest blogger
“Python is great and its ecosystem for scientific computing is world class. HDF5 is amazing and is rightly the gold standard for persistence for scientific data. Many people use HDF5 from Python, and this number is only growing due to pandas’ HDFStore. However, using HDF5 from Python has at least one more knot than it needs to. Let’s change that.”
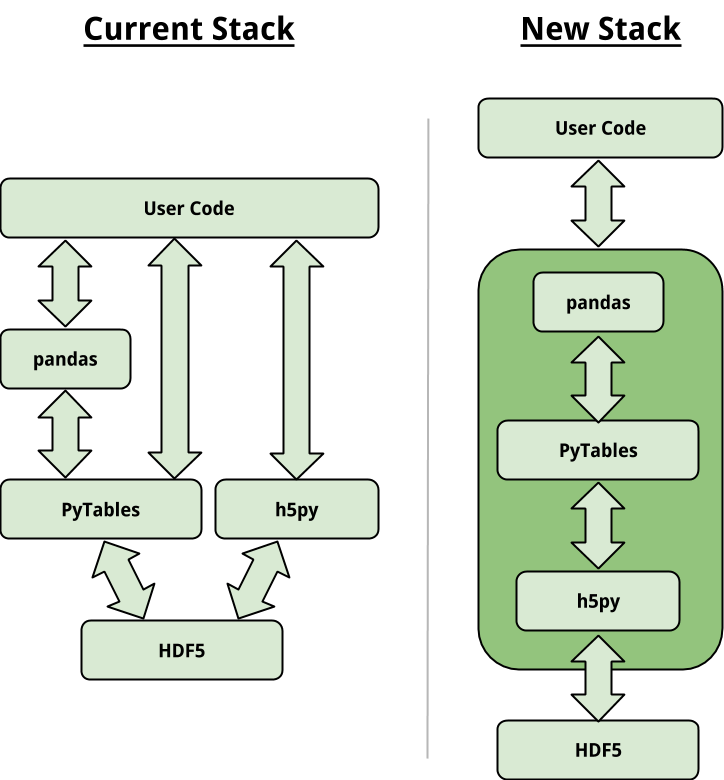
 Almost immediately when going to use HDF5 from Python you are faced with a choice between two fantastic packages with overlapping capabilities: h5py and PyTables. h5py wraps the HDF5 API more closely using autogenerated Cython. PyTables, while also wrapping HDF5, focuses more on a Table data structure and adds in sophisticated indexing and out-of-core querying. Which package you use depends on your use case – and sometimes you really need both!
Almost immediately when going to use HDF5 from Python you are faced with a choice between two fantastic packages with overlapping capabilities: h5py and PyTables. h5py wraps the HDF5 API more closely using autogenerated Cython. PyTables, while also wrapping HDF5, focuses more on a Table data structure and adds in sophisticated indexing and out-of-core querying. Which package you use depends on your use case – and sometimes you really need both!
At SciPy 2015, developers from PyTables, h5py, The HDF Group, pandas, as well as community members sat down and talked about what to do to make the story for Python and HDF5 more streamlined and more maintainable. Here is what we came up with:
- Refactor PyTables to depend on h5py for its bindings to HDF5.
- Update h5py to support the PyTables refactor (some data types are needed, etc.).
- PyTables will keep all of its high-level abstractions.
- Make h5py – PyTables interactions seamless.
- Ensure API and HDF5 file backwards compatibility for both h5py and PyTables.
- Major version number bump for PyTables, and maybe h5py.
We believe that users and developers will both benefit from this. You will no longer be forced to choose between h5py and PyTables up front. Instead, you’ll be free to move up or down the stack as you want or need to.
The refactor effort is about more than technical superiority. We also see it as a merging of communities. While the projects will remain separate – they fill different niches – they are becoming even more symbiotic than they have been. We believe the refactor will bring more users to both h5py and PyTables. As an important gesture to this end, the core developers for h5py now have push rights to the main PyTables repository and vice versa. We are committed to seeing this vision come to pass.
Sustainability, Maintenance, and Funding
Something like the proposed new stack has to occur in the long run for the Python and HDF5 ecosystem to remain viable. There is no reason for there to exist two, canonical low-level binding libraries to HDF5. It is a redundant effort not just for the core developers, but also for the community of users. The current situation means that there are now two places where bugs could be reported, two places where nasty unicode issues could come up, two handles to your HDF5 files in memory, and so on. This is unsustainable.
We believe that the proposed refactor is the best way to address these long standing maintenance issues. PyTables has been around as long as anything. Seriously, work on PyTables began in 2001 – this is before NumPy, as long as IPython, etc. It might be tempting to think that PyTables can go along its merry way. But PyTables has only been around for so long because it has adapted to meet the needs of the day. Right now, the best way for any of the codes to survive is to work together.
Of course, the best way to ensure that these changes happen is for us to receive funding. This could come from one very generous source, or from multiple organizations. We see three avenues that we’d like to see funded:
- The refactor, requiring ~6 months to 1 year FTE, split between PyTables and h5py.
- Long-term maintenance issues: such as release management, CI, bug fixes, mailing lists responses, etc., for h5py and PyTables requiring ~3 months FTE per year.
- New and novel feature implementations:
- Columnar data format – We’ve wanted this in PyTables for many years. Matt Rocklin does a great job of explaining the idea.
- Faster read/write
- Improved compression
- Dynamically add fields
- Single Write-Multiple Read support
- Rich
getitemindexing, à la pandas. - Improved Indexing and Querying for multi-dimensional datasets, à la dask.
- and more!
- Columnar data format – We’ve wanted this in PyTables for many years. Matt Rocklin does a great job of explaining the idea.
A major problem with fundraising, though, is the question of, “Where does the money go?” Well, we are excited to announce that we have solved this problem because…
PyTables is now a NumFOCUS Project!
As of August 29th, 2015, the PyTables’ core developers have signed a comprehensive fiscal sponsorship agreement with NumFOCUS (NF), a 501(c)3 non-profit for scientific computing. We are honored to join with the ranks of IPython/Jupyter, Matplotlib, Julia, SymPy, Software Carpentry, Data Carpentry, and others. More importantly, we can accept tax-deductible donations for Python and HDF5 activities. This includes hiring people to do the work described above. We are super excited.
For individuals seeking to give to the projects, we will have a PayPal link soon. For larger organizations, please contact the core developers of PyTables or h5py or NumFOCUS. We are more than happy to write competitive proposals. If you know of any and would like us to apply, please let us know.
If you are a potential funder and are restricted from giving to non-profits, don’t worry! Both h5py and PyTables have core developers who are able to PI projects at R1 universities in the United States.
Of course, if coding is more your style, we always will review any pull requests that come through. If you need help getting started, just ask us and we’ll happily guide you along.
So no matter who you are, or what your interest is, we are here, ready, and able to help make Python & HDF5 work even better together than they already do. The proposal here is what we want and is the result of wall-clock months of collective effort. Many of us cannot afford to see these projects disappear. Streamlining the stack will help ensure that both h5py and PyTables are healthy and vibrant for the foreseeable future.
Please, let’s make this vision become a reality!
PyTables Governance Team – Anthony Scopatz, Francesc Alted, Antonio Valentino, Andrea Bedini
h5py Core Developers – Andrew Collette
Acknowledgements
Huge thanks to NumFOCUS for providing us with fiscal sponsorship. The importance of this cannot be understated.
Many thanks to The HDF Group (Mike Folk, John Readey, and Gerd Herber in particular) for encouraging and engaging with us throughout this whole process.
Editor’s Note: Anthony has made many wonderful contributions to the HDF5 cause, including his aptly-titled “HDF5 is for Lovers” tutorials. Thank you, Anthony!
Related Links:
http://www.pytables.org/FAQ.html#how-does-pytables-compare-with-the-h5py-project
For information about NumPy, pandas, and IPython, see. https://www.hdfgroup.org/2015/07/hdf-at-scipy2015/.
For more about h5py: https://www.hdfgroup.org/2015/03/hdf5-as-a-zero-configuration-ad-hoc-scientific-database-for-python/.
NEW 9/25/15: More comments on Reddit – https://www.reddit.com/r/Python/comments/3m231l/python_hdf5_a_vision_pytables_will_be_refactored/
This is a fantastic move. No more split-egg problems in data persistence or crunching. Curious to see what the new datatypes will be. Is there a roadmap available somewhere? I’d like to take a look at it to see if I could potentially contribute…
Hi Arjun, We don’t have a roadmap per say. But we do have a lot of work to do. If you are not already on the PyTables user’s or developer’s mailing list, please join one of those and ask this question. We can go from there. Thanks!
Maybe NumFOCUS’ support cannot be *overstated*?
We have a need to use hdf5 1.10 virtual datasets using h5py. Is there a ETA on supporting virtual datasets in hdf5?
For all of you wanting to see this happening, we are happy to inform you that we just started the process for doing this and we would be glad to receive contributions to this effort. For details, see: https://github.com/PyTables/PyTables/blob/pt4/doc/New-Backend-Interface.rst