by John Readey
“For Heaven’s sake, do not confound HDF5 with anything else!”—Friedrich Nietzsche, Ecce Homo |
Alan Turing devised the Turing test (he referred to it as the “Imitation Game”) in 1950 to determine whether a machine could think. He believed that if machines could give answers that were indistinguishable from human answers, then they must be viewed as having intelligence.
While systems like ChatGPT are not (quite) there yet as far as thinking goes, we can apply the same strategy to ask a question about HDF5: Suppose you were given two software packages, one the HDF5 library and the other an impostor; what are the “questions” you could ask to distinguish the two?
Here is my list of questions that we can put to the two packages in an attempt to find the impostor:
- Do both packages support the HDF5 API?
- Do programs run against the two packages produce equivalent results?
- Are the data files produced by the two packages equivalent?
Do both packages support the HDF5 API?
Question #1 asks if the two packages both support the HDF5 API. If the program doesn’t compile with package A but does with package B, that’s a good sign that A is the impostor! Of course, most everyday users of HDF5 only use a small percentage of the functions available in the HDF5 API, but if we wanted to be thorough, we could use the HDF5 test suite itself as our validator.
Do programs run against the two packages produce equivalent results?
Let’s suppose both packages pass this first test. But two packages just having the same API signatures is a rather low bar. Our next question goes one step further and asks if a given program run against the two packages produces the same result. That is, if Question #1 could be passed by compiling the HDF5 test suite against each package, this question would require building and running the test suite against both packages and having the test suite report the same results (expected failures and all!)
This is a high standard of fidelity and for most purposes we can accept the two packages as interchangeable. If we get the same answers for each set of API calls, what other means would there be to distinguish the two?
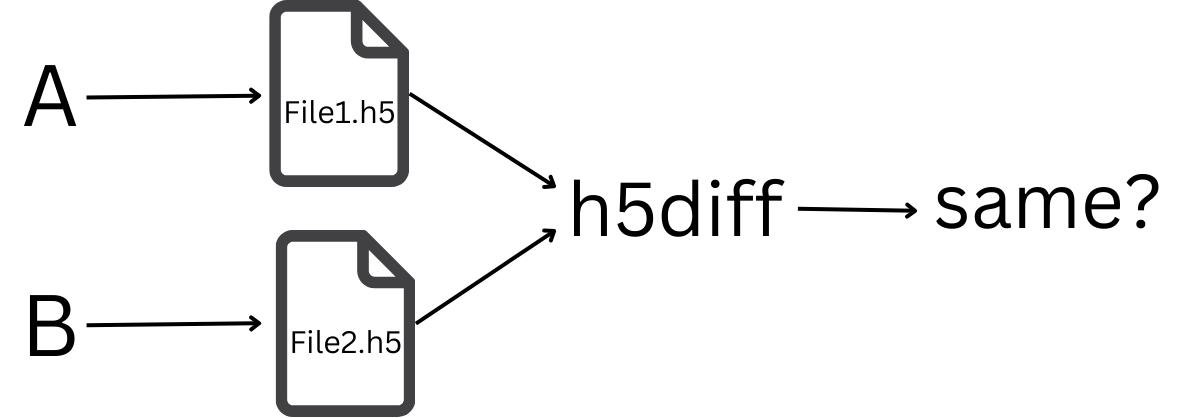
Well, one idea would be to look at the artifacts created by the program. For example, assuming our test program creates a new HDF5 file or modifies such a file, we’d expect the files to be equivalent. Here, we need to be a little careful about what we mean by equivalent. Even if we used the HDF5 library for both runs, the resulting HDF5 files wouldn’t be binary identical (e.g., the files may contain different timestamps).
However, the h5diff utility (one of the tools that come with HDF5) can be used to judge if two HDF5 files are the same in terms of the HDF5 data model—having the same groups, datasets, attributes, links, and so on. And furthermore that each element of each dataset is the same in the two files.
Are the data files produced by the two packages equivalent?
So, for our third test, we will compare the HDF5 files produced by our program using the two mystery packages, by running h5diff using the two HDF5 files as arguments to h5diff. We’ve found our impostor if h5diff reports that the two files are different.
If our impostor passes all these tests, then we have to conclude that at least as far as correctness goes (we’ll put aside possible performance differences for now), there’s no real difference between hdf5lib and brand X.
Ok, so this has been an interesting discussion, but what’s the practical significance of this thought experiment? Though I’m not aware of any implementations that attempt to completely replicate the HDF5 library, there’s always been an interest in alternative means of representing the HDF5 data model. For example, perhaps I would use an SQL database rather than files for storage. To ease the burden of implementing these alternative implementations, The HDF Group developed the “Virtual Object Layer” (VOL), a plug-in architecture that lets developers substitute an implementation that intercepts HDF5 API calls at a fairly high level and substitutes its own implementation for the underlying storage operations. The HDF5 library’s default filesystem operations are actually implemented as one of these VOL connectors, called the “Native VOL”.
Since the VOL has been incorporated into the HDF5 library, a fair number of VOL connectors have been created. You can see a list of registered VOL connectors on the support site.
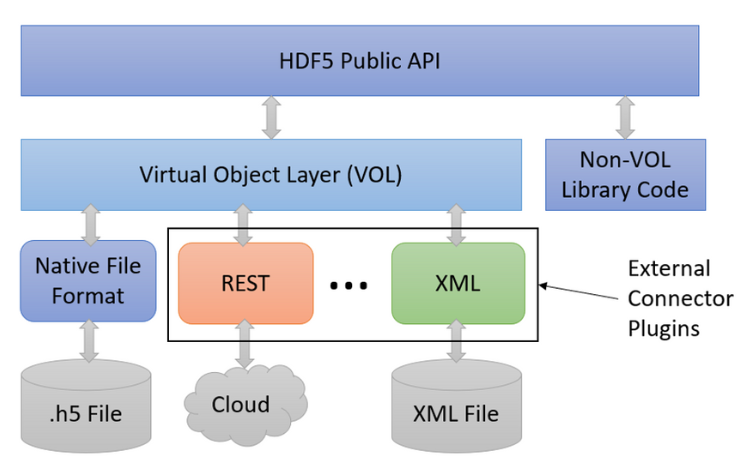
So now the question comes to light: “if a VOL connector X is used in place of the native VOL connector is it really HDF5 or something else?”. The Turing Test methodology would say that if we can’t discern any difference via external testing using a particular VOL connector, then we should consider that as genuinely HDF5. Which is not to say that if we can see a difference, the result is not HDF5. Often, a VOL is created for a particular use case, and it’s sufficient for some core subset of features to work. Also, most VOLs are a work in progress as it can be quite a long road to full HDF5 compatibility.
An Example: The REST VOL
As an example, let’s take a look at the REST VOL. The REST VOL is a VOL connector that replaces filesystem reads and writes with HTTP requests using the HDF REST API. To accept and process these requests we’ll use HSDS, a Python-based web service for reading and writing HDF data. Can the REST VOL + HSDS imitate the default HDF5 lib with high enough fidelity to pass our version of the Turing test? Let’s review our list of questions again and see how it works.
Does the HDF5 with REST VOL support the HDF5 API?
The first question would be, “Does the HDF5 with REST VOL support the HDF5 API?” This is trivially true, as the HDF5 Public API operates at a higher level than a VOL connector and must be used to interface with them. So, actually, any VOL connector should pass this test (even if it is completely non-functional).
Does the HDF5 test suite pass using the REST VOL connector?
Of course just having the API entry points doesn’t mean that those calls will function in the same way as with the default library, so let’s move on to the second question: “Does the HDF5 test suite pass using the REST VOL connector?”. Here, we need to point out that the HDF5 test suite doesn’t always play fairly. In addition to public API calls, the test suite sometimes uses internal library functions which may have no analog in a VOL implementation. The need to support testing of VOL connectors led to the development of a new test suite using only the public API functions. The API tests are still quite new and, unfortunately, not comprehensive, but it’s the best tests we have currently that can substantively test different VOL connectors. So, we’ll use that as our equivalence checker—if a VOL connector passes the API test suite, we’ll take that as a sign of high fidelity. It should be noted that the API tests are fairly lenient—many HDF5 features aren’t covered, e.g., Region References. However, we can still say that if all the VOL tests pass for a given connector, that connector supports a broad selection of HDF5 functionality. Furthermore, it indicates a high probability that a given application can switch to that VOL connector and still run correctly without any source code changes.
So how does the REST VOL do with this test suite? In the past, not so well, but over the last year, many improvements have been made to the REST VOL and several new features were added to HSDS specifically to support REST VOL requirements. Currently almost all tests pass. The only exception is tests that use some data types not currently supported by HSDS, namely bitfield and opaque types. The good news is that these are not very commonly used, and many applications will run just fine as-is. Hopefully, these types will be added in the near future and we can have 100% of the API tests supported.
On the flip side, there are things that work with REST VOL that don’t with the default library. For example, the core library with the ROS3 VFD is restricted to interacting with s3 objects in a read-only way. However, the REST VOL with HSDS supports both reading and writing to s3 buckets, reflecting one of the core missions of HSDS. This doesn’t help us pass the Turing test, but most would consider it very useful for doing the full range of HDF5 operations in the cloud.
Another example is support for multiple writer/multiple readers (MWMR as opposed to SWMR – Single Writer, Multiple Readers). With REST VOL + HSDS, MWMR is supported while with the default HDF5 library MWMR is likely to lead to file corruption issues. At the risk of failing the HDF5 Turing test, we’ll take support for MWMR as a win.
Are the HDF5 files produced by the REST VOL equivalent to those made by the HDF5 default library?
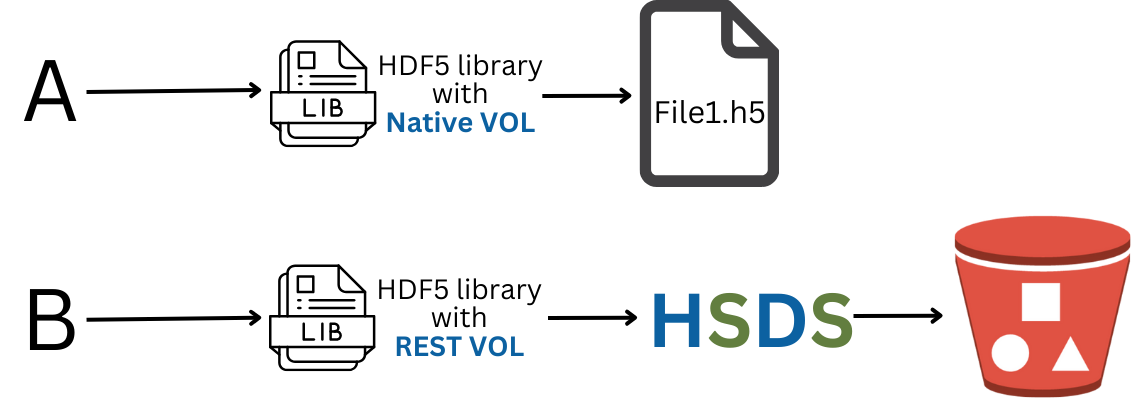
Let’s move onto our final question: Are the HDF5 files produced by the REST VOL equivalent to those made by the HDF5 default library? In one sense the answer is obviously no. The HSDS uses a sharded storage model where object metadata is stored in JSON, and chunks are stored as binary blobs. In another sense, the REST VOL + HSDS does pass this test. There are two command line utilities that are useful in this context: hsget and hsload. With hsload you can convert an ordinary HDF5 file into the HSDS sharded schema. Conversely, hsget will take a HSDS domain (the HSDS equivalent of a file) and convert it to an HDF5 file. With hsload and hsget, HDF5 files are round-trippable. You can take an HDF5 file, use hsload to upload it to HSDS, then use hsget to recreate an identical (in the hsdiff sense) HDF5 file to the one you started with. Similarly, a program using the default HDF5 library to create an HDF5 file will produce an equivalent HSDS domain as the following diagram illustrates.
So to answer this third question, we’ll perform one extra step: use hsget to transform the output of the REST VOL to end up with an HDF5 that is hopefully equivalent to what would have been produced by the Native VOL. As before we’ll use h5diff to verify the files are equivalent.
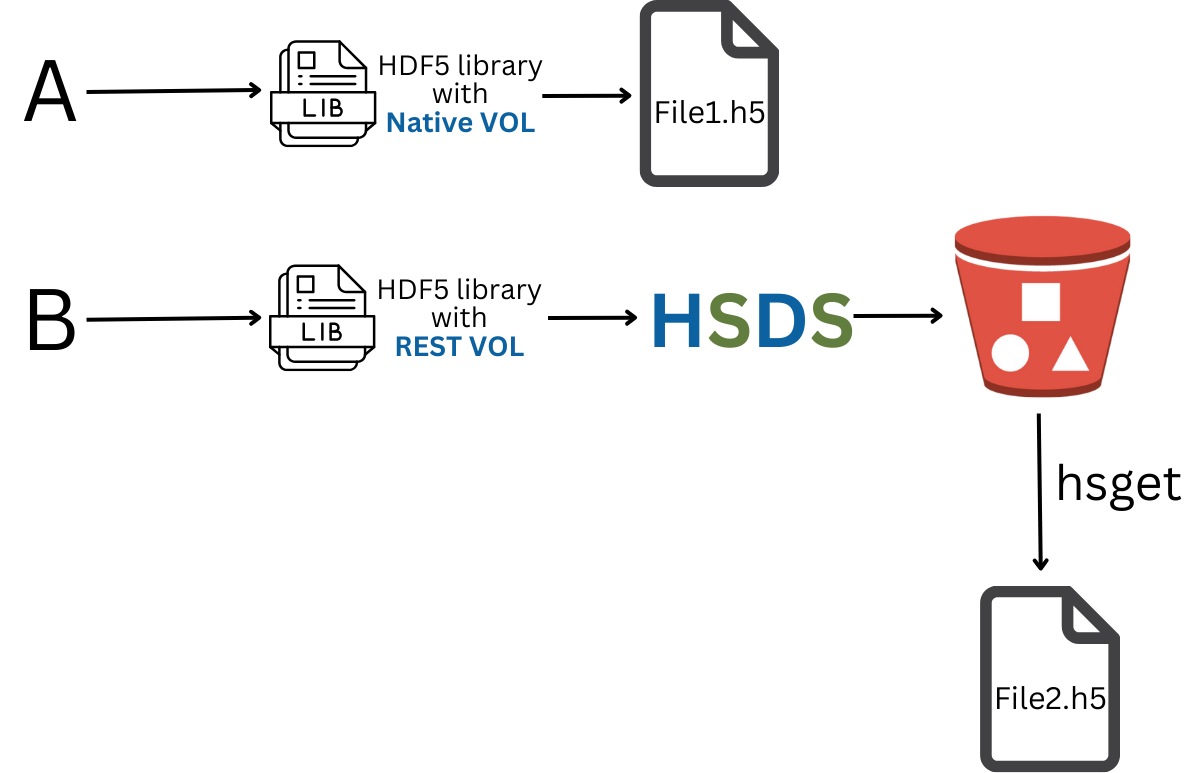
REST VOL with HSDS passes this test, so we can conclude that in most cases nothing is lost by utilizing HSDS when it fits your use case—for example, you wish to replicate processing performed locally in the cloud.
Conclusion
We’ve reached the end of our short discourse on a Turing test for HDF5. Hopefully you’ll not need to worry that the creation of VOL connectors have flooded the world with HDF5 impostors, but instead find the reach of HDF5 is broadened to take on more challenges and keep pace with new technologies. HDF5 has been around for 25 years now. No one knows what the future holds, but there is a good chance that over the next 25 years HDF5 will still be in the toolbox of everyone who works with scientific data.
Have questions about VOL connectors or HSDS? Join the discussion at https://forum.hdfgroup.org/.