HSDS Services
HDF Data Products & Solutions provide turnkey, managed data products and HDF Cloud support and consulting for The HDF Group’s Highly Scalable Data Service (HSDS)—our open source REST-based solution for reading, writing, and sharing data within object-based storage environments such as the Cloud (POSIX storage works as well). Utilize HSDS and our ready-to-use solutions to quickly integrate seamlessly within your preferred storage environment and optimize the way you access, query, compute and collaborate with HDF5® data.
HSDS Azure VMA VM zero-touch appliance for Azure. |
HDF Cloud Support ServicesWork with The HDF Group staff to install and customize HSDS on your existing infrastructure. |
Interested in learning more about HSDS? Contact the HDF Group today to see which solution is right for you.
What is the Highly Scalable Data Service (HSDS)?
As many organizations face the challenges of moving their data to the cloud, for many, major code changes and cost increases are top concerns.
HSDS is a REST-based solution for reading and writing complex binary data formats within object-based storage environments such as the Cloud. Developed to make large datasets accessible in a manner that’s both fast and cost-effective, HSDS stores HDF5 file using a sharded data schema, but provides the functionality traditionally offered by the HDF5 library as accessible by any HTTP client. HSDS is open source software, licensed under the Apache License 2.0. Managed HSDS products, support, and consulting is offered through HDF Group’s HSDS Products and Solutions.
HSDS Products and Solutions provide users turnkey implementations of HSDS and customized training, support, and consulting. Our experts can provide guidance and assistance from early adoption of HSDS to implementing and deploying enterprise solutions. We can help you ensure project success and avoid missteps so you can quickly overcome your unique data challenges. Contact us to learn more.

Why use HSDS?
The benefits of the Highly Scalable Data Service (HSDS) extend over almost every need organizations have for their data, regardless of file format:
- Scalability: Store petabytes of data, scale across multiple servers, and dynamically change the number of server nodes to meet client demands.
- Performance: Leverage smart data caching to accelerate object storage queries, process requests in parallel on the server, and run existing HDF5 applications faster by utilizing the automatic parallelization features of HSDS.
- Concurrency: Supports multiple writers/multiple readers (even to the same file), simultaneous access from thousands of clients, and multithreaded applications.
- Simplicity: Deploy with one-click, transfer only the data you need, and work with your cloud provider of choice.
- Compatibility: Rapidly shift large HDF5 files, applications, and infrastructure to the cloud; compatible with all HDF5-based conventions (e.g. NetCDF4, Energistics, etc.); and existing applications can use HSDS with minimal changes (HDF5 API and Python h5py API compatibility).
- Security: HTTP and HTTPs supported; clients don’t need direct access to cloud storage; Role Base Access Control (RBAC) can be used to easily manage group access; and Access Control Lists (ACLs) enable control on which users have access to individual data files.
- Reliability: Multiple copies of each object are stored (no danger of data being lost) and object updates are atomic, so no danger of files being corrupted.
- Portability: Use AWS S3, Azure Blob, MinIO, or Posix storage; Docker, Kubernetes, Azure managed Kubernetes (AKS), AWS Kubernetes (EKS), and DC/OS container management systems are all supported; and move between on-prem deployments to the cloud without application code changes.
- Cost: Use low cost AWS S3 storage (or other object storage systems); use GZIP or BLOSC compression to reduce storage costs; and no proprietary software required.
How does HSDS work?
HSDS is implemented as a set of containers where the number of containers can be scaled up or down based on the desired performance and expected number of clients. The containers can either be run on a single server (using Docker) or run across a cluster using Kubernetes. The architecture of HSDS, explained in detail below.
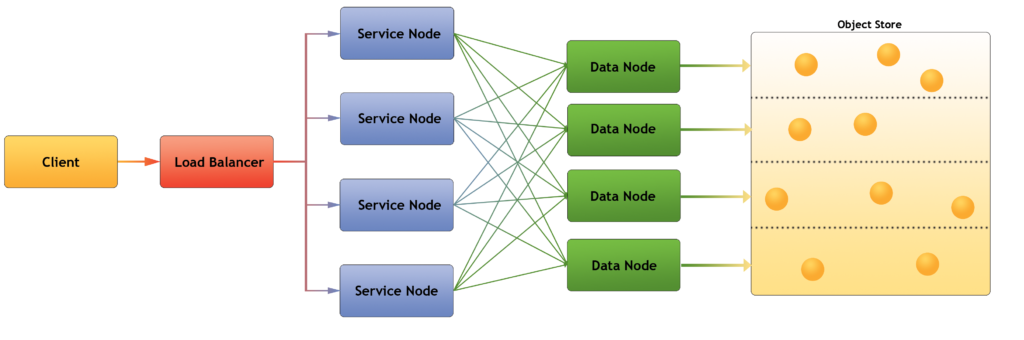
There are two classes of containers, the service node and the data node.
The service nodes are the containers that receive requests from the clients. For each request, the service node, authenticates the request, verifies the action is authorized (e.g. delete an object, add an object), then then forwards the request to one or more data nodes
For their part, the data nodes, access the object storage system (e.g. S3) to read or write the requested data. Each data node maintains a cache, so that recently accessed data can be returned directly without having to go to the storage system. The data nodes maintain a virtual partition of the storage system, so that each node is responsible for a distinct subset of the objects (a files objects will typically be distributed across all partitions).
For HDF5 datasets, one object is created for each chunk in the dataset. When clients send requests to read or write data across multiple chunks, each data node can be performing IO in parallel. So while with the regular HDF5 library, these types of operations require each chunk to be processed sequentially, with HSDS the operation can be performed much faster.
In addition to providing functional equivalents to the HDF5 library, like compression, hyperslab and point selection, HSDS also supports many features not yet implemented in the library, including
- multi-reader/multi-writer support,
- compression for datasets using variable length types,
- SQL-like queries for datasets, and
- asynchronous processing.
Additionally, HSDS offers its own set of client library tools and utilities:
- REST VOL, a HDF5 library plug-in that clients can use to connect with HSDS
- H5pyd, a Python package for clients to connect with HSDS
- HS command line interface, standard Linux and HDF5 utilities for importing, exporting, listing content, etc.
Existing code can be easily repurposed to read/write data from the cloud using the REST VOL (for C/C++/Fortran applications) or h5pyd (for Python scripts) allowing organizations to easily move their data to the cloud without a large expenditure in re-writing code.
This 2020 webinar covers the basics of the Highly Scalable Data Service. Support for HSDS can be obtained through The HDF Group’s Forum (requires registration) or through a service contract.
Next Steps
HSDS Source Code
The source code for Highly Scalable Data Service (HSDS) is available on Github. You’re welcome to access the source code under the permission Apache License 2.0. As a non-profit, The HDF Group does offer commercial product services around HSDS to help with the setup, installation, maintenance, and training around HSDS.
Equinor Case Study
The Atmos Data Store team from Equinor have been working with The HDF Group over the last couple of years to incorporate the Highly Scalable Data Service (HSDS) as part of their system for managing hundreds of terabytes of metocean (meterological and oceangraphic) data. Read the blog post about this project.
NREL Case Study
The U.S. Energy Department’s National Renewable Energy Laboratory (NREL) released the WIND Toolkit – a portion of a 500 TB dataset accessible to the public using HSDS. Among other functions, users can interact with the dataset with this interactive online visualization tool which also utilizes HSDS to quickly serve slices from the massive dataset through a web browser. Read the press release and case study.
HSDS Products and Solutions
HDF Cloud Support Services. The HDF Group staff will install and customize HSDS on your existing infrastructure. Contact us for a quote.
HSDS Marketplace Products. HSDS Azure VM is a turn-key solution for those with data on Azure.Supports multiple writers/multiple readers (even to the same file)
Support simultaneous use from thousands of clients