By Francesc Alted. He is a freelance consultant and developing author of different open source libraries like PyTables, Blosc, bcolz and numexpr and an experienced programmer in Python and C. Francesc collaborates regularly with the The HDF Group in different projects.
We explain our solution for handling big data streams using HDF5 (with a little help from other tools).
In the ubiquitously connected world that we live in, there are good reasons to understand what data is transferred across a network and how to extract information out of it. Being able to capture and log the different network packets can be used for many tasks including:
- Protecting against cyber threats
- Enforcing policy
- Extracting and consolidating valuable information
- Debugging protocols/services
- Understanding how users use your network
However, the high-speed nature of modern networks makes capturing and logging these data packets an important challenge, even when using modern multi-core computers with high speed I/O disks. Part of the problem is that the data from network packets needs to be pre-processed before being ingested, and doing that for a large number can be expensive.
Recently The HDF Group approached this problem with the aim of being able to pre-process and store data messages at a sustained speed of no less than 500K messages/sec and along the way, demonstrate that HDF5 is a perfect match for storing and further analyzing this data. Here is how we achieved that.
A Publisher-Subscriber solution
The problem consisted of ingesting information coming from a network appliance in charge of sniffing network packets and extracting specific data and metadata from them. The appliance generates different data streams (up to 12 in our case), each one containing different aspects of the network packets. Here is our final approach for the ingestion application:
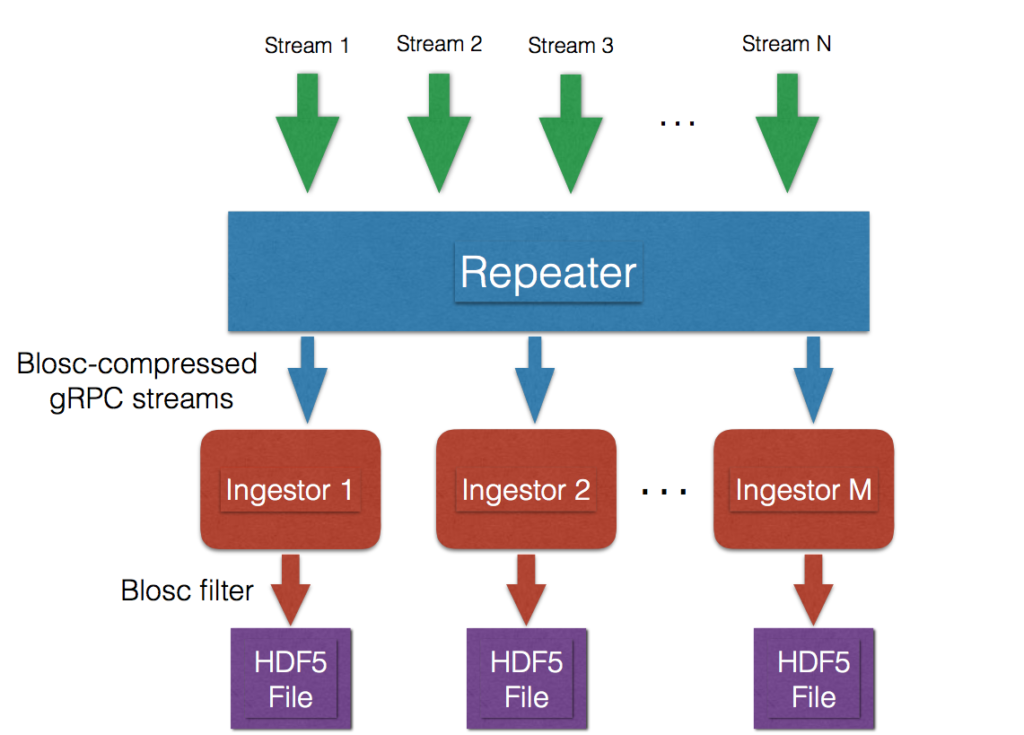
In this diagram we can see how the streams are processed inside of a so-called “Repeater.” The Repeater is in charge of producing new streams made from a selection of the incoming ones, which are then re-sent to different “Ingestor” processes for storage in HDF5 files.
The new streams are transmitted using the gRPC protocol which allows users to define the schema of messages (via Protocol Buffers) and transmit them very efficiently. In addition, these messages are compressed with the fast Blosc compressor for maximum throughput. The combination of gRPC + compression makes it possible to efficiently send the new streams to other computers, even outside of the local LAN.
Let’s learn more about the Repeater by looking into its components:
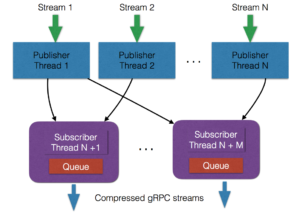
So we can see here how every incoming stream is associated with its own “publisher” thread, and that there can be any number of subscribers that are interested in receiving this stream. This allows for a flexible way to setup new ingestors meant for storing just a selection of incoming streams. As the different publishers and subscribers work on their own thread, this allows the generation of outgoing streams totally independent of each other. This is critical for having different ingestors storing data separately and without blocking the whole process (Embarrassingly Parallel Problem).
In order to deal with traffic peaks, every subscriber has an internal queue with buffers where the messages are aggregated until they are ready for transmission. Here it is how this has been implemented:
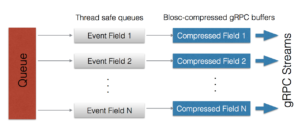
During the transmission of a buffer, the queue can still handle incoming messages, so buffering is not stalled at any time. Also, the queue is split in different sub-queues that are specialized in storing data of the same type together. This additional step is important to allow the compressor to get not only much improved compression ratios, but also faster operation. Once each one of these specialized queues is full, it is compressed and sent to the ingestor via a gRPC stream.
Ingesting the gRPC streams
When the outgoing gRPC streams are setup, we just needed to setup a ingestor service that receives and stores them. As gRPC is specially efficient in transmitting binary data, this service can be put in the same machine or a remote one. Because the average size of the messages is around ~100 bytes, the compression ratio is about ~5x and the goal was storing about 500K messages/second (for a full subscription), that accounts for a required bandwidth of ~10 MB/s (~80 Mbps) which is quite achievable for modern WAN networks, allowing for a relative freedom for placing the ingestor (e.g. we don’t need to put it in the same rack as the Repeater).
Regarding storage, as HDF5 is meant for writing binary data in large data blocks, the gRPC data buffers are uncompressed and sent to the file as a whole. Furthermore, a compression filter can be activated in HDF5 too, reducing the size of the stored data and allowing the logging of a much larger amount of messages using the same resources. As using compression puts less pressure to the I/O disk bandwidth, any mechanical disk would be enough to keep the ingestion going. However, the analysis may require a larger bandwidth, so the ingestor manager may need to make some decisions about the required performance of storage media. At any rate, the HDF5 library itself proved not to be a bottleneck for such relatively low I/O speeds.
Implementation details and problems found
The Repeater service was completely implemented in Java, mostly for leveraging its great multi-threading capabilities, as well as its wide range of high-performance blocking queue structures. The ingestor was implemented in Python, mainly for simplicity. gRPC was used as the glue allowing to communicate the Java and Python worlds in a very efficient and transparent way.
During the implementation a lot of effort initially went in trying to deal with the large throughput of messages. We soon realized that working with different small messages individually was not going to work. When we made the decision to store many messages in a large buffer, everything went much smoother (and faster). Finally, by decoupling the different fields in messages into separate buffers, we achieved the desired processing speed of > 500K messages/sec (actually the ~650K mark was achieved for our specific machine).
Make no mistake, despite all the optimizations, the Repeater needs to run in a server with lots of RAM (> 128 GB) and cores (> 20). Having such a large amount of RAM is important for buffering the traffic peaks in incoming streams, whereas the many cores are needed so as to keep with all the incoming streams (~12) and subscribers working in parallel without bottlenecks.
Overview and lessons learned
We were able to deal with the problem of ingesting a large number of streams from different clients by using a series of techniques:
- Separation of concerns: by splitting responsibilities in smaller subsystems we were able to focus on improving specific functionality without worrying about the others. Using patterns (e.g. publisher/subscriber) and easy-to-use remote procedure call systems and transport layers (gRPC and protobuf) were critical to achieve this.
- Buffering: dealing individually with small messages is expensive; grouping them in buffers makes things much faster.
- Binary storage: when dealing with structured messages, using a binary format like HDF5 is a big win because it optimizes the required storage, while allowing the user to endow the data in a hierarchical structure that is important for the analysis phase.
- Compression: allows for much better bandwidth utilization and also, less required space (up to 5x less) for storing the binary data in HDF5 files.
- Future proof: using HDF5 as the persistence layer ensures that data can be archived in long-term storage silos, provided the *extreme* stability of the format.