Gerd Heber, The HDF Group
| Editor’s Note: Unfortunately, the ODBC project is currently sunsetted. We developed the ODBC connector, but the demand was not large enough to justify the expense to Simba for licensing their portion of the project. That is also why we are not able to redistribute the binaries that were created. If you would like to talk to someone from The HDF Group about funding development on the ODBC driver, please contact us. |
In the face of naysayers, the SQL abides. Read in our latest blog post how HDF5 and ODBC tie the room together.
When I order my HDF5 at Moe’s Data Diner, I usually ask for extra napkins. It’s a meal where you need both hands, and it can be messy before you get to the juicy bits. At least that’s the way it used to be. It’s easier to dissect with h5py [8], but what’s the hungry stranger to do, who is just coming through town and who is clueless? When asked the other night, I didn’t fall off my chair nor did I choke, but the question got my head going. What would it look like, that SQL on-the-side thing?
Say, I have an HDF5 dataset at /group1/A/dset2 and would like to select a few elements like so:
SELECT * FROM /group1/A/dset2 WHERE value > -999.0
Nice, but how do I get the result into my favorite analytics tool? Isn’t there some standard pipe or conduit that helps me over that last mile? Well, it’s kind of embarrassing to admit, but it’s been there since the early 1990s and is called Open Database Connectivity (ODBC) [4].
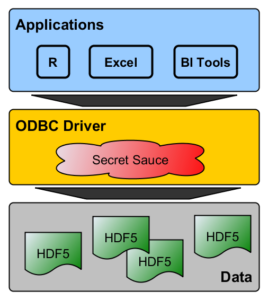 Think of ODBC as the “USB of data sources.” If you have a USB driver for a device, it’s game on. If you have an ODBC driver for your data source, then it’s SQL, milk, and honey from here. A growing number of applications come with some module or package for accessing data stored in HDF5 files, but you can be almost certain that your tool of choice has an ODBC client built in.
Think of ODBC as the “USB of data sources.” If you have a USB driver for a device, it’s game on. If you have an ODBC driver for your data source, then it’s SQL, milk, and honey from here. A growing number of applications come with some module or package for accessing data stored in HDF5 files, but you can be almost certain that your tool of choice has an ODBC client built in.
To build an HDF5/ODBC driver, we need a splash of the “secret sauce” shown in the figure above, and this is the subject of this blog post. Spoiler Alert: We are not giving away the recipe.
Instead, we describe its taste and flavors in somewhat bland technical terms. Notwithstanding that, let’s start with a hands-on example.
Excel’s Other Data Source(s)
Most of us have probably loaded data from a text or CSV file into Excel, but its data import capabilities don’t stop there. On the Excel Ribbon, the “ODBC goodness” is hidden under the Data tab in the From Other Sources menu.
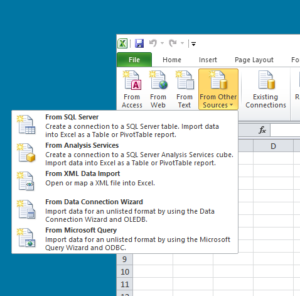
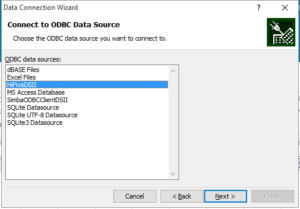
Select From Data Connection Wizard and pick ODBC DSN as the kind of remote data source you want to connect. After hitting Next, you’ll be presented with a dialog similar (the actual list of ODBC data sources might be different for your system) to the one shown below. Select the HiFiveDSII data source and you’ll be prompted for the name of an HDF5 file.
The Data Connection Wizard will then present you with a list of tables from which you can import data, or against which may run more sophisticated SQL queries. See the figure below for a sample table list from an HDF-EOS5 file.
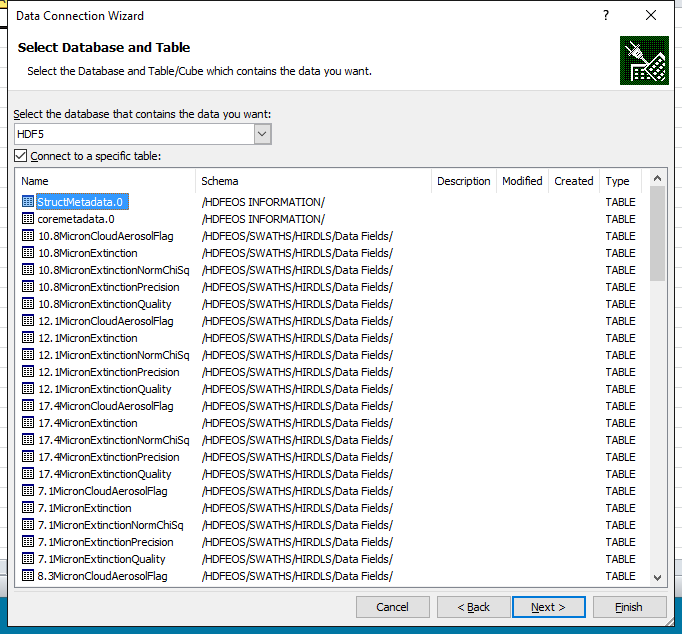
This is essentially a list of HDF5 path names with the dataset names as table names. Pick one, hit Import, and see the data delivered to your doorstep (worksheet). Caution: If you’ve picked an HDF5 dataset whose element count exceeds the maximal number of rows in an Excel worksheet (1,048,576), you’ll be presented with a warning and a choice, to continue with a truncated subset or to abort the import.
Happy days! Why wasn’t it always this easy? Consider this the “Hello, World!” of HDF5/ODBC. Now, what do you say after you say hello?
List of Ingredients and Nutritional Information
Warning: The material presented in this section is subject to change. It gives you an idea of what we have implemented to date, but the final product might be different.
HDF5 Datasets as ODBC Tables
HDF5 datasets seem to be the natural candidates for making an appearance as tables on the relational side. Leaving aside more sophisticated storage layouts [6], the closest thing to a table in HDF5 is probably a one-dimensional dataset of a compound type, such as a time series, with the fields of the compound type representing table columns. (See the figure below.)
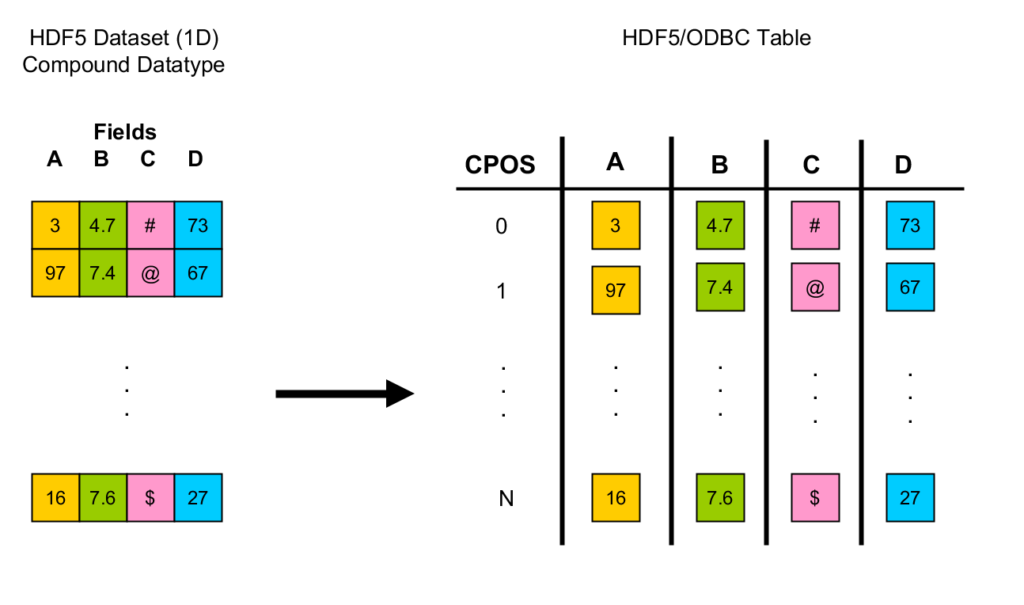 The ODBC standard supports an assortment of scalar types (integers, floating-point numbers, strings, etc.) and thereby delineates the subset of HDF5 datatypes that can be faithfully mapped to SQL types. Currently, if an HDF5 datatype cannot be converted to an SQL type, it is suppressed by the driver, i.e., the corresponding dataset is not exposed at all, or the corresponding field in a compound type is unavailable. You are probably aware that the values of HDF5 datasets are (logically) dense rectilinear arrays. However, the relational model has no notion of table dimensionality; a table holds a set of rows. Most RDBMS vendors support row identifiers, but this is not a relational concept either. It’s unclear what most users would find beneficial. For now, the HDF5/ODBC driver provides tables as row sets of dataset elements with an additional column, CPOS, which for each row contains the linearized C-array index of the underlying dataset element. (See the figure below.)
The ODBC standard supports an assortment of scalar types (integers, floating-point numbers, strings, etc.) and thereby delineates the subset of HDF5 datatypes that can be faithfully mapped to SQL types. Currently, if an HDF5 datatype cannot be converted to an SQL type, it is suppressed by the driver, i.e., the corresponding dataset is not exposed at all, or the corresponding field in a compound type is unavailable. You are probably aware that the values of HDF5 datasets are (logically) dense rectilinear arrays. However, the relational model has no notion of table dimensionality; a table holds a set of rows. Most RDBMS vendors support row identifiers, but this is not a relational concept either. It’s unclear what most users would find beneficial. For now, the HDF5/ODBC driver provides tables as row sets of dataset elements with an additional column, CPOS, which for each row contains the linearized C-array index of the underlying dataset element. (See the figure below.)
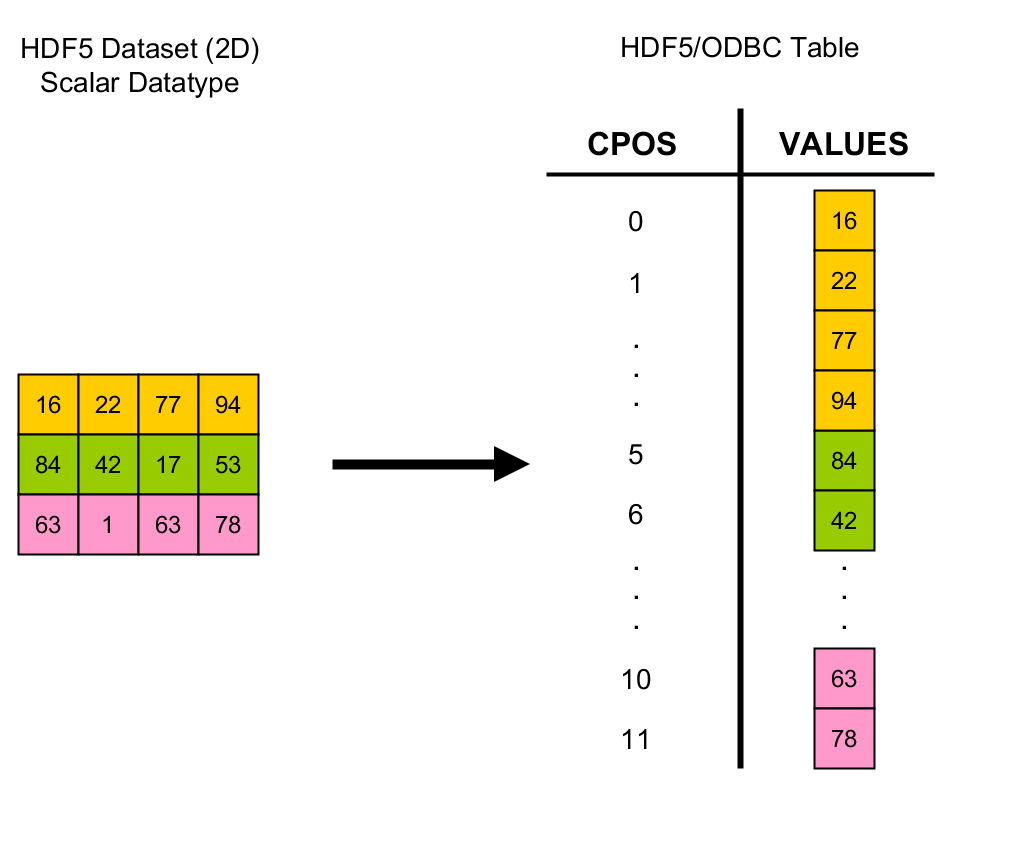 If this is not what you’d expect, let us know what you think should be the default behavior! As we’ll see in a moment, it’s quite easy to support different behaviors.
If this is not what you’d expect, let us know what you think should be the default behavior! As we’ll see in a moment, it’s quite easy to support different behaviors.
Read-Only
The current version of the HDF5/ODBC driver is a one-way street, it’s read-only. Yes, the ODBC standard covers modifying operations such as INSERTs and UPDATEs, but the first version of our driver will be a read-only affair.
One HDF5 File = One ODBC Resource (for now)
To keep this discussion simple, let’s assume there is a one-to-one correspondence between databases (=ODBC data sources) and HDF5 files. (I know, you have 10,000 HDF5 files, and you don’t want 10,000 separate databases. You could get around this limitation, for example, using mechanisms such as external links and virtual datasets [5], and create a single HDF5 file view of your collection. In the release version of the driver, we might support more convenient methods, but let’s not get carried away.)
Client/Server
Let’s think about file location for a moment. The HDF5 file might just sit on your desktop or in a file system attached your machine. Let’s call this the standaloneconfiguration of the ODBC driver deployment. In the figure below, this is shown on the left-hand side. In this mode, the ODBC driver is just a shared library running in the context of your client application processes.
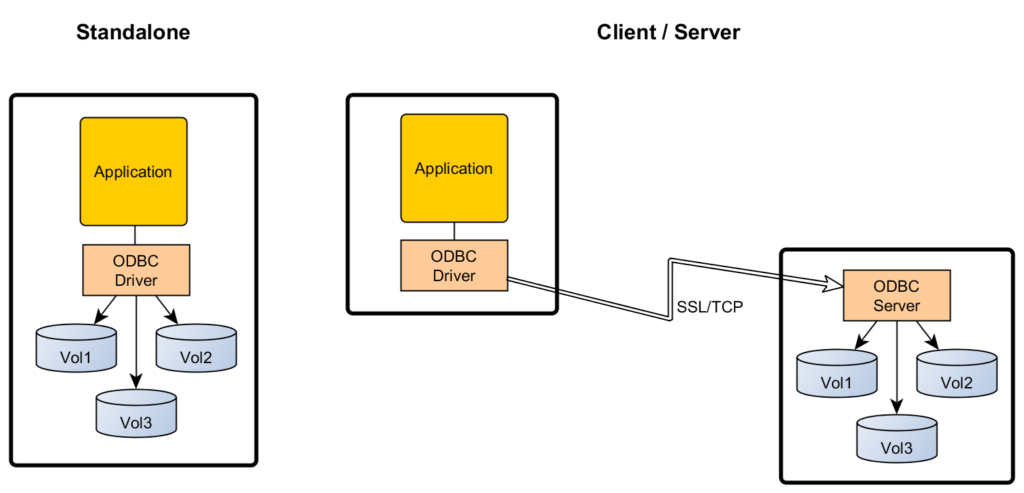
If the file is stored on a remote server, you will get the same appearance as long as you can connect to the remote host via TCP. In this case, there will be an ODBC server process running on the remote machine, handling requests from ODBC clients. Let’s call this the client/server configuration of the ODBC driver deployment, which is shown on the right in the figure above. The HDF5/ODBC driver supports both configurations.
(Default) Schema on Read
Since HDF5 datasets are not usually created with SQL in mind, there is no prescribed schema for SQL to use to interpret the data. We resolve this by employing so-called schema on read. This refers to an environment’s ability to impose a schema at read time, regardless of how the data is stored.
A table name is a three part construct:
<CATALOG>.<SCHEMA>.<TABLE>
For this discussion, think of CATALOG as synonymous with ‘database.’ By default, in HDF5/ODBC, the CATALOG name is HDF5. SCHEMA represents an individual user’s (or a group of users) view of the data stored in the catalog, including access permissions, etc. The TABLE part is what we usually associate with table names when writing queries. Thus, in our case, TABLE typically represents an HDF5 dataset.
For example, let /group1/A/dset2 be an HDF5 path name of a dataset. By default, the HDF5/ODBC driver would present this dataset to an application as the table
HDF5.”/group1/A/”.dset2.
(In SQL, names containing non-alphanumeric characters must be included in double quotation marks.)
What about HDF5 attributes?! The default view exposes HDF5 attributes in a table called HDF5.VRTL.Attributes. This table has three string-valued columns, ObjectPath, AttributeName,
AttributeValue, which represent the HDF5 path name of the attributee, the attribute name, and attribute value, respectively.
For some of you the default view might be of limited use. It’s just a “relational HDF5 baseline.” You can customize the HDF5/ODBC driver’s behavior with an XML-based configuration file. It gives you total control over the catalog name, the schemata, and table names. You choose which datasets to show (or to hide), and which fields of a compound type to expose, and what the column names should be. At the moment, the configuration file creation is a manual process, but there might be some helper tools included in the release version.
Ok, enough technical detail already. Let’s see a more elaborate example!
Make Sure You Get Enough R
If you’ve read the previous sections and had some exposure to R [7], then the following script should be easy to follow. Otherwise, just read the comments.
# load the RODBC module and create a connection to the ODBC resource “Demo”
library(RODBC)
con<-odbcConnect(“Demo”,believeNRows=TRUE, readOnlyOptimize=TRUE)
# print the table names in schema “/tickdata/”
tbls<-sqlTables(con, catalog=“HDF5”,schema=“/tickdata/”)
print(tbls$TABLE_NAME)
readline(“Press <return to continue”)
# run a query against an HDFEOS dataset and calculate avg., med. and stdev.
data<-sqlQuery(con,
paste(“select VALUE from HDF5.\”/eos/HDFEOS/SWATHS/HIRDLS/Data Fields/\”.O3″,
“where VALUE > -999.0”))
cat(“mean:”,mean(data[[1]]),” median:”,median(data[[1]]),“stdev:”,sd(data[[1]]),“\n”)
readline(“Press <return to continue”)
# read and plot a time series
data<- sqlQuery(con, “select * from HDF5.\”/tickdata/\”.\”18-09-2011\””)
plot(data[[2]],data[[3]])
# count the number of HDF5 attributes and print the distinct attribute names
print(sqlQuery(con, “select count(*) from HDF5.VRTL.Attributes”))
data<-sqlQuery(con, “select distinct AttributeName from HDF5.VRTL.Attributes”)
print(data[[1]])
# close the connection
odbcClose(con)
Personally, I’m not fond of the R syntax, but I could say the same about celery stalks, and look at those nutrition facts!
A Cautionary Tale of Two Bridges
In the book ZeroMQ[1] [2] , a conversation between two engineers ends like this:
The first engineer was silent. “Funny thing,” he said, “my bridge was demolished about 10 years after we built it. Turns out it was built in the wrong place and no one wanted to use it. Some guys had thrown a rope across the gorge, a few miles further downstream, and that’s where everyone went.”
Without bridges to other ecosystems, HDF5 is just another island with all the joys and eccentricities of island life. At present, HDF5/ODBC is a floating bridge because it might be misplaced, and some of its assumptions might be flawed. Hence this invitation to join the discussion and help us find the right place for that more permanent arch, beam, or suspension bridge to take its place.
What’s Next
We are currently planning for a Q2 2016 release of the product. In the meantime, we are working with a few early adopters on finalizing the initial feature set. If you have additional questions about HDF5/ODBC, or if you would like to become an early adopter, please contact us by sending an email to odbc@hdfgroup.org.
References
|
[1] |
ZeroMQ by Pieter Hintjens, O’Reilly 2013 |
|
[2] |
|
|
[3] |
An Introduction to Database Systems by C.J. Date, Pearson 2004 |
|
[4] |
ODBC 3.5 Developer’s Guide by Roger E. Sanders, McGraw-Hill 1999 |
|
[5] |
|
|
[6] |
|
|
[7] |
|
|
[8] |
Python and HDF5 by Andrew Collette, O’Reilly 2013 |
Hi Gerd
Sometime ago I started doing the same thing, an SQL parser for HDF5.
1) What kind of SQL parser are you using? Or developing your own?
2) What will be the behavior regarding SQL types that are not present in HDF5 (like time and date)?
3) Are you going to use the HDF5 Table API?
4) Is the ODBC driver going to be written in C/C++?
5) Is it possible for me to have access to the prototype you are writing?
Thanks
-Pedro
1) We are using a third-party SQL parser.
2) Notice that version 1 is read-only, and those types will be just ignored. We have ideas on how to deal with them in future versions, but it’s too early to say anything definitive.
3) (Version 1 is read-only.) At the moment, we have no plans to support the HDF5 Table API or PyTables in version 1. That will most likely change in future versions.
4) It is written in C++.
5) There will be trial versions available early next year. Which platforms / clients interest you?
Best, G.
One other pattern that might be useful is to treat a series of 1-D datasets having the same length as a “table”. The reason being is that 1-D Compound Datasets don’t allow attributes to be associated with each member. As such they are not great for storing measurement data from multiple transducers during a test since the metadata support is weak. With a series of 1-D datasets you can hang a rich amount of much meta-data off each dataset (i.e. “transducer”)
So I guess an option such as “aggregate same sized 1-D datasets into one table”. Would be a way to implement it. if you had a group with some high frequency sampled data (e.g. series of 1-D array datasets of length 1M rows) and some lower sampled data (e.g. series of 1-D array datasets of length 10K rows), you would get two tables.
That’s definitely one of the use cases we are considering at the moment. The release version of the driver will be built on HDF5 1.10. Virtual Datasets (VDS) might be in some cases sufficient to achieve what you’re describing. We also have a more declarative way (via XML) under development, which doesn’t require the user to create any VDS, and which will offer additional flexibility beyond VDS.
Best, G.
Yes, this is the kind of schema I am interested in too. I use such a schema already for Python/R work, and it would be great to make the data SQL-accessible.
This would be fantastic. I’m looking for a way to create a shared “master” dataset for a group of users. They all use different analysis tools – SAS, Python, Julia, R, etc. and mostly work independently. I’m looking for a good way to maintain a single dataset (easy for me) that users can pull subsets of based on their specific needs/criteria (easy for them). The queries are often based on values – date ranges, amounts, etc. Read-only would be fine for them.
What’s the current status of this as of August 2016? (And I don’t suppose there’s any chance of a JDBC version of this?)
We are just wrapping up the beta test, and it’ll be available in October (2016). A JDBC driver won’t be part of the first release, but might be an option going forward.