Mark Miller, Lawrence Livermore National Laboratory, Guest Blogger
The HDF5 library has supported the I/O requirements of HPC codes at Lawrence Livermore National Labs (LLNL) since the late 90’s. In particular, HDF5 used in the Multiple Independent File (MIF) parallel I/O paradigm has supported LLNL code’s scalable I/O requirements and has recently been gainfully used at scales as large as 1,000,000 parallel tasks.
What is the MIF Parallel I/O Paradigm?
In the MIF paradigm, a computational object (an array, a mesh, etc.) is decomposed into pieces and distributed, perhaps unevenly, over parallel tasks. For I/O, the tasks are organized into groups and each group writes one file using round-robin exclusive access for the tasks in the group. Writes within groups are serialized but writes across groups are concurrent, each occurring independently to a different file.
A competing approach to multiple independent file is single, shared file (SSF). These two approaches differ in how concurrency in I/O operations is managed. In MIF, concurrency is managed explicitly by the application writing to separate files whereas in SSF, it is managed implicitly by the I/O interface and file system writing to a single, shared file.
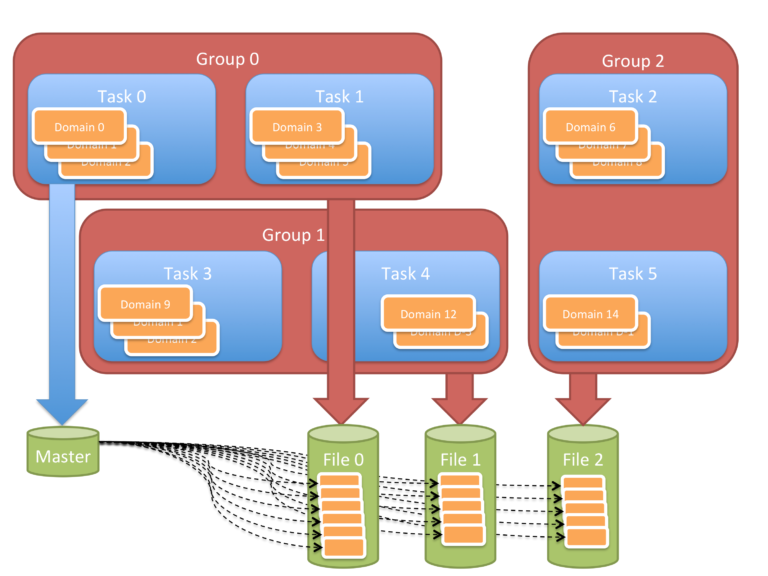
In the example in the diagram, the computational object is decomposed into 16 pieces, called domains, distributed among 6 tasks. Some tasks have 3 domains and some have 2. Tasks are formed into 3 groups each group producing one file. Finally, a small “master” file is written to capture information on how all the pieces are distributed among the files.
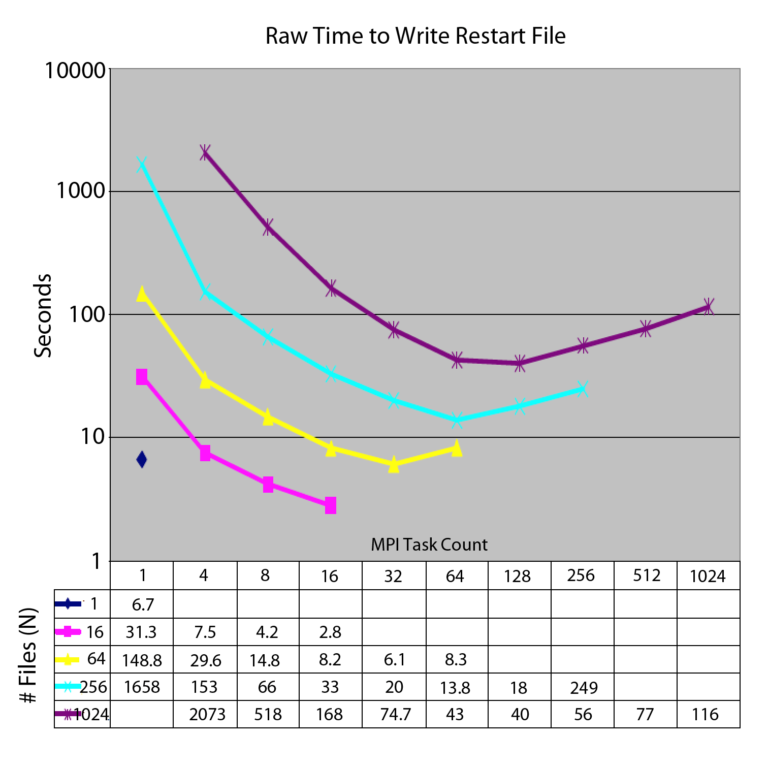
In MIF, the number of files (or, equivalently, the number of groups) determines the amount of concurrency. Two extremes are worth elaborating. Setting the number of files equal to the number of parallel tasks results in file-per-processor I/O. This may result in an unwieldy number of files but is ideally suited to certain recently proposed HPC platforms with local persistent storage (e.g. “burst buffers”). Setting number of files to 1 effectively serializes I/O. This is unacceptable at even slightly above small scale but is often convenient for tiny scale. Ideally, the number is chosen to match the number of independent data pathways between the nodes of the running application and the file system; too large and contention for resources slows performance; too small and resources are under utilized. There is an optimal file count for maximum performance as the data from a 1999 study below shows. In practice, file count is chosen heuristically by the user approximately logarithmically proportional to task count. For example, at O(106) scale, maybe 4096 files are optimal.
MIF is often referred to as N:M whereas SSF is often referred to as N:1. N:M means N tasks writing to M files whereas N:1 means N tasks writing to 1 file. Likewise, N:N means N tasks writing to N files and is really just a special case of N:M where M=N. Unfortunately, this N:X terminology emphasizes numbers of tasks and files but obscures the most distinguishing feature of these approaches; how concurrency is managed; independent file concurrency or shared file concurrency.
Support for MIF in HDF5
Among its many attractions, more of which are detailed later in this article, the MIF paradigm works even for serial I/O libraries and involves an extremely easy-to-use parallel programming model. In particular, the HDF5 library includes a number of features, already available and/or nearing completion, that facilitate or help to optimize MIF.
Probably the most important among these is HDF5’s group abstraction which supports a hierarchical namespace for objects in a file. This is essential to MIF because it allows each task to write identically named pieces of some larger decomposed object in separate groups in the same file without name collisions. In addition, the ability of HDF5 to do recursive object copies of whole groups makes it easy to migrate individual task outputs from the MIF paradigm between and within files.
Next, the implementation of HDF5’s metadata cache is such that only the portion of the object namespace visited by an application is loaded into memory. This is critical to ensuring an upper bound on memory footprint and consistent file open and close performance as the number of objects in a file grows. Recently, LLNL funded The HDF Group’s work to improve memory footprint of the metadata cache and to optimize and simplify metadata cache configuration for MIF and other HPC use cases.
HDF5’s external links and soft links combined with file mounts also facilitate MIF. Either of these choices enables a data producer to create a master file that appears to a consumer as though all the objects in all the other files virtually reside within the master. Consumers need not be burdened with the fact that data is actually scattered across many files. Nonetheless, consumers are still exposed to the fact that an aggregate data object, like a parallel decomposed array, is actually a collection of object pieces in HDF5.
However, a recent addition to HDF5, virtual datasets, addresses even this issue by capturing information about how individual HDF5 datasets are knitted together to form a single, coherent whole dataset. For example, there could be 1024 different datasets each representing a 10242 slice of a 10243 volume scattered about 32 files. A single virtual dataset in the master file would enable consumers to only ever see and interact with it as a 3D, 10243 dataset. With virtual datasets, consumers need not even be aware of the fact that the object is decomposed into pieces let alone that those pieces reside in different files.
The core virtual file driver (VFD), which is essentially a ram-disk, is another feature of HDF5 that often facilitates a specific kind of MIF, file-per-processor or N:N. When a data producer has sufficient memory, HDF5’s core VFD permits it to aggregate all I/O activity into a single, behemoth whole-file I/O request occurring during file open and close operations. Once opened, all HDF5 calls made by the application wind up interacting with the file in memory like a ram-disk. The whole file is read or written to the file system in a single I/O request.
In addition, in 2013 LLNL funded an enhancement to the core VFD to support file images. An application can either deliver or acquire a raw buffer of bytes to/from HDF5 to treat as a file. File images facilitate MIF by enabling an application to, for example, open a master file for reading on one task and then broadcast it to other tasks which in turn open and read the buffer instead of requiring each task to hammer the file system to read the master file.
More recently HDF5’s file image feature has been used to support dynamic load balancing. A basic problem in dynamic load balancing involves the ability to message pass a piece of the computational object between tasks. But, in sophisticated, multi-physics applications, a piece of the computational object typically involves a complex collection of related data structures. Writing the code to serialize, message pass and un-serialize this data is onerous. But, a MIF application already has the code necessary to do this to/from files. Can such I/O code be easily adapted to message pass “domains” between tasks? Yes. And, HDF5’s file image feature is the solution. The application invokes the logic ordinarily used in MIF I/O to write a domain to a file except instead it writes it to memory using HDF5’s core VFD. The file image feature allows access to the raw bytes representing this file in memory and the application message passes the buffer to another task. The receiver task uses HDF5’s file image feature to open these bytes as an HDF5 file and then invokes the MIF I/O code to read it. Magically, using HDF5’s file image feature the same code needed to support MIF I/O is easily adapted to support dynamic load balancing.
Finally, LLNL has funded and work was recently completed on two additional features in HDF5 to facilitate MIF. These are the page buffering and metadata aggregation features. Page buffering is designed to enforce all I/O operations occur in application specified page sizes and alignments and to maintain in memory no more than an application specified number of cached pages of the file. Page buffering is absolutely critical to ensuring I/O performance on newer HPC platforms where I/O nodes are fewer, fatter and optimized for larger, page-oriented (>=1Mb) transfers. The metadata aggregation feature is designed to collect HDF5 metadata together in large blocks and to reduce co-mingling of HDF5 metadata with application raw data in the file address space. Page buffering ensures I/O requests emitted by HDF5 can be tuned to underlying hardware and file system architectural parameters. Metadata aggregation ensures that metadata I/O is large and frequently accessed metadata is kept together. Combined, page buffering and metadata aggregation will improve performance of any HPC parallel I/O paradigm and certain aspects of the MIF paradigm (namely file handoffs between tasks within a group) in particular.

MIF Pros and Cons
We’ll start with the cons.
MIF Cons
- In MIF, large, parallel, decomposed data objects are managed always as a collection of pieces. For example, in the picture above, instead of treating a mesh as a single, massive object, in MIF it is always treated as a bunch of mesh pieces (different colored regions in the picture) which, in general, can be irregular in both size and shape. This manifests in HDF5 as a collection of dataset objects, each representing one piece.
- The decomposition is fixed. It cannot be easily changed. Typically, in MIF workflows there exist whole applications whose sole purpose is to read an old decomposition and then compute and write a new one.
- There are overheads associated with managing the data always as a collection of pieces. This includes possible Halo or ghost data surrounding each piece as well as the data necessary to knit neighboring pieces back together when necessary. As pieces get smaller, these overheads get relatively worse. Consequently, MIF is not always suitable for strong scaling scenarios.
- Querying information about the global object can be tricky, or worse, very costly. For example, how many array elements does the global array comprise? Or, what are its global extents? Answering even these simple questions about the global object may require visiting all the pieces (e.g. opening all the files) and/or doing the knitting necessary to assemble the global whole object.
- MIF produces many files. At large scale, the shear number can place a strain on file system metadata resources. Common operations like ls or stat can slow or stall. Moving and sharing data can often involve the extra steps to tar up the files, move them and then untar them. Individual files or the master file can sometimes be missed or lost.
- Each application in a MIF workflow needs to be designed to interact with the data in pieces distributed among many files. Applications that are sensitive (at least locally if not globally) to how pieces knit together need to have logic to support that. Without careful attention this data management logic can wind up being duplicating in data producers and consumers.
Before we move to all of the pros of MIF, lets refute some of these cons.
MIF Cons Are Not All Bad
- It is almost never an issue that the decomposition is fixed. MIF decompositions are designed to be over-decomposed by some small factor, K. The size of the pieces is such that K pieces will fit within the available memory of each parallel task. Given 60 pieces, for example a MIF application can run 1:1 on 60 tasks, 2:1 on 30 tasks, 3:1 on 20 tasks or even 3:1 on 12 together with 4:1 on 6 of 18 total tasks. MIF applications have great flexibility in allocating compute resources for a given decomposed object.
- Halo or ghost data overheads can often be confined to compute and removed from persistent storage during I/O. When pieces are written, halo data is stripped away and when they are read, it is re-generated. Likewise, because it is fixed for a given decomposition, neighbor knitting data can be written once and re-used as necessary.
- Although MIF overheads suggest poor strong scaling behavior, strong scaling of I/O alone, as opposed to compute alone or compute plus I/O, has little practical application. Furthermore, network and I/O latencies to global persistent storage are more likely to dominate strong scaling behavior than any MIF overheads.
- The challenges in computing queries on global objects in MIF workflows are almost irrelevant because such queries are never performed in isolation. In other words, we never encounter a situation where we allocate resources to compute a global query, and only that global query. Furthermore, in MIF workflows, any information about the global object that is frequently needed is typically pre-computed and stored in the master file for quick lookup.
- Although the MIF paradigm can generate a multitude of files, especially at large scale, this is easily mitigated by distributing files over a directory tree and providing users with meta tools (e.g. alternatives to mv, cp, ls, stat, etc.) that treat directory trees and file sets as solitary objects. Developing such tools does represent an additional software maintenance burden but is small in the context of whole MIF workflows.
- Indeed, all applications in a MIF workflow must be designed to interact with data in pieces distributed among many files. LLNL made this investment close to 20 years ago and has been reaping the rewards of the MIF approach ever since.
MIF Pros
The MIF paradigm has many more pros than cons. Some of the pros are specific to the use of HDF5 while many are generally true for any I/O library. We’ll discuss those that are generally true first.
- MIF is a much simpler programming model because it frees developers from having to think in terms where one task’s I/O activities are intertwined with another’s. With the exception of the message passing necessary to manage exclusive access to a file for each task in a group, MIF permits developers to think about and develop I/O code that is basically serial in nature. For large multi-physics applications where the size, shape and even existence of data can vary dramatically among tasks, this is invaluable in simplifying I/O code development. The value in this simplified programming model cannot be understated. Its simple to develop, debug and maintain parallel I/O code using the MIF paradigm.
- Good performance demands very little in the way of extra/advanced features from the underlying I/O hardware and file system. A relatively unsophisticated file system can get it right and perform well. However, MIF does require that file system metadata operations scale well.
- MIF supports file-based data subsetting. In MIF workflows, it is easily possible to deal with a subset of the data, even on a laptop, by dealing with just some files. In addition, a MIF file set is more easily managed by a larger set of candidate file systems because each file is less likely to exceed any file system’s maximum file size. Whereas, in an SSF paradigm, the files are so behemoth only the most cutting edge, HPC-centric scalable, parallel file system technology is able to handle them.
- The use of locking to implement POSIX I/O semantics is unnecessary for MIF. Recent HPC I/O literature is rife with authors pontificating the need to eliminate POSIX I/O due to the use of locking to implement various POSIX semantics. However, these semantics are really only necessary for SSF. MIF is far less impacted by POSIX locking and in most if not all cases can be made to work in the absence of such locking.
- Application controlled throttling of I/O is easily supported in MIF because the number of concurrent operations is explicitly controlled. This can help to avoid overwhelming the I/O subsystems with contention for I/O requests.
- MIF alleviates any need for global-to-local and local-to-global remapping upon every exchange of data between the application and its file as is so often required in SSF workflows.
- When run in file-per-processor mode, MIF can easily take full advantage of burst buffers implemented using local persistent storage. In contrast, the SSF paradigm cannot exploit such hardware. In particular, the Scalable Checkpoint and Restart (SCR) library works in concert with MIF.
- A variety of advanced features of HDF5 work in concert with MIF but do not work with SSF. Presently, this includes any HDF5 operations requiring chunked storage. This includes all types of filtering and most importantly, compression. (The HDF5 Group has recently developed solutions for compression in parallel.) In-transit compression works fine with MIF but does not work with SSF. In addition, application level checksumming via HDF5 also works fine with MIF but does not work with SSF. HDF5’s core VFD also will not work with SSF but works perfectly well with MIF.
- In almost all respects, MIF is totally analogous to the way modern commercial big data I/O in map-reduce operations is handled. There, data sets are broken into pieces and stored in a file system as a collection of pieces called shards. Different numbers of parallel tasks can process different numbers of shards. If the commercial sector finds this paradigm worth billions of dollars of investment, its probably a well vetted approach.
We have described the MIF Parallel I/O paradigm and described a number of HDF5 features that facilitate MIF. We have also shown that the advantages of MIF far outweigh any shortcomings. In addition, we have shown that several shortcomings are either non-issues or easily mitigated.
To the author’s knowledge, the MIF parallel I/O paradigm was first implemented using Silo in the late 1990’s by Rob Neely, then the lead software architect for the Ale3d simulation code. Since its resounding success there, and because of its easy-to-use parallel I/O programming model, the same approach has been adopted and used by a majority of LLNL flagship simulation codes as well as codes developed elsewhere within the scientific computing community.
This work was performed under the auspices of the U.S. Department of Energy by Lawrence Livermore National Laboratory under Contract DE-AC52-07NA27344. This article is identified by release number LLNL-JRNL-698378.
Editors Note: Mark M. Miller (LLNL) – Mark’s early support was essential in the development of HDF5. He contributed technically through his co-authorship of AIO, the LLNL I/O library adopted by NCSA as the prototype basis of HDF5, and also by a never-ending stream of ideas. Thank you, Mark!
Thanks, Mark for a great article!