The Atmos Data Store team from Equinor have been working with The HDF Group over the last couple of years to incorporate the Highly Scalable Data Service (HSDS) as part of their system for managing hundreds of terabytes of metocean (meterological and oceangraphic) data. They’ve graciously agreed to provide some background on their project and how they use HDF5 for their solution.
1. What are the goals of the “Atmos Data Store” project?
Equinor is a global energy company that operates in Oil & Gas and the Renewable Energy sector. Most of the operations are located offshore. To secure safe and efficient operations and being able to design robust offshore infrastructure, the company needs to have a good understanding of metocean conditions at the site—that is the study of atmospheric, wave and current conditions. In this context, success is highly dependent on the data quality, i.e. the statistical representation of metocean data, and the expertise of metocean engineers. The metocean data consists of measurements representing snapshots of reality (typically, 1-3 years in time and one point in space) and numerical models providing statistically sufficient amount of data (typically 40+ years in time and covering huge areas, containing terabytes of data). The metocean engineers analyze this data to prepare a basis for design of offshore structures or planning offshore operations.With the company’s expansion into the Renewable Energy sector comes a bigger need for metocean analysis. This increased demand requires the metocean engineers to operate efficiently with terabytes of data. The “Atmos Data Store” is a set of data product offerings that aims to transform the way in which Equinor manages and analyses metocean data. It addresses known bottlenecks of working with big data by providing a cloud-based platform for efficient storage and distribution of metocean data, enabling engineers to discover, search for and access the data they need within seconds. Additionally, the automated analytic capabilities of the Atmos Data Store free up engineers from repetitive and time-consuming tasks, allowing them to focus on more critical and value-adding activities.
2. How did you come to use HDF5?
Working with big data requires:
- Efficient data structure
- Compression and chunking capabilities
- Easy and quick access to the parts of the data without reading the whole dataset
- Metadata that describes the contents of the file, including the variables, units, and dimensions
NetCDF format (More precisely: NetCDF4 which is built on HDF5) is designed for atmospheric, oceanographic, and geophysical data and meets all requirements listed above. This format is widely used in the atmospheric modeling community and is well-described in CF Metadata Conventions project in terms of its structure. Additionally, the format has good user support in Python community, with tools like xarray, h5py, netcdf4 and more. Based on the reasons above, we chose to adapt the NetCDF4 format in this project. To ensure compliance with the NetCDF format, we established acceptance criteria and developed a database of naming conventions compliant with the CF conventions. Standardization of the source data facilitates efficient data management, reduces the risk of errors or confusion when working with multiple datasets, and results in fewer lines of code required to process and transfer the data. To ensure incoming files are compliant with these rules, an open-source convention-checker is available at https://pypi.org/project/atmos-validation/.
3. Can you provide a high-level description of the system architecture?
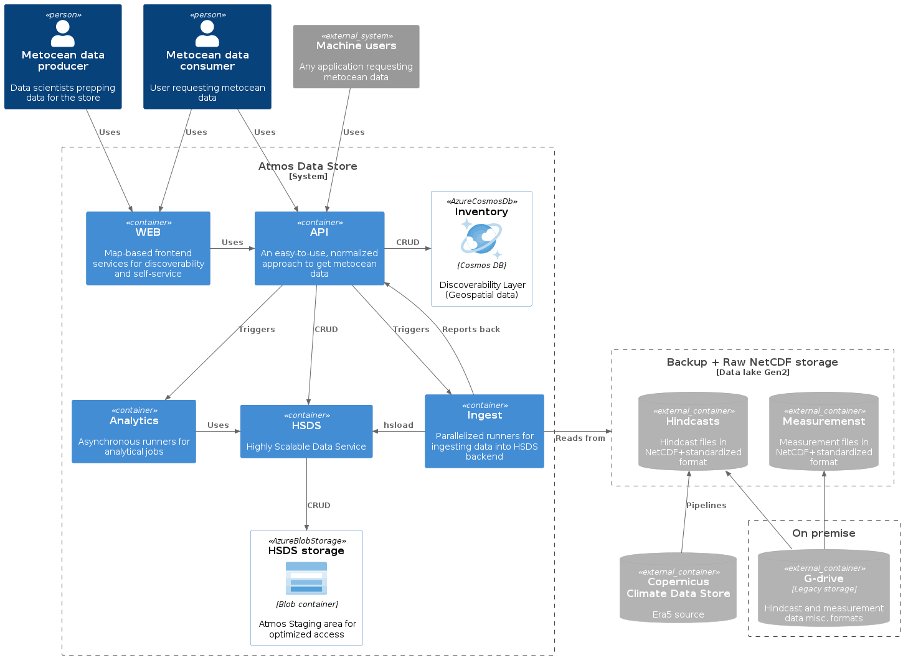
Our aim is for the user to be able to retrieve any data product on their own—from searching, filtering, discovery to understanding the data access requirements, quality, limitations, and appropriate uses for the data, to finally obtaining the actual data or analytics they need to do their job. The context drawing from our architecture diagrams is shown below, where:
- Data producers: data scientists producing or collecting data.
- Data consumers: users or any application requesting metocean data.
- WEB: Map-based frontend servicing a user-friendly interface for accessing data and analytics.
- API: An extensive library of APIs for managing, discovering and accessing metocean data.
- Inventory: A NoSQL database service which holds information about the data in the Atmos Data Store. This holds a geospatial representation of the source data with domain references to HSDS. We choose (Serverless) Cosmos DB due to its low cost and its support for Geospatial indexing, giving users the ability to search for data using geometries. Also used for searching and filtering on other data properties. Storage size: ~15MB for ~4000 datasets.
- Analytics: Asynchronous runners for longer-running analytical jobs. Runs on the same compute as HSDS to not invoke egress/ingress costs.
- Ingest: Import module for loading data from raw (and backup) storage into HSDS storage using hsload utility.
- Data Lake Gen2: Holds the NetCDF files to be ingested to HSDS storage.
- HSDS: HSDS handles requests for reading/writing data to Azure Blob Storage. HSDS runs as a set of pods in Kubernetes which allows the service to scale as needed.
- HSDS Storage: The cloud storage used by HSDS to store the NetCDF files using a sharded data schema. Storage size: ~100TB for ~4000 datasets / domains.
- External containers: E.g. External sources (e.g. Copernicus CDS), legacy storage, and other external data sources. These sources provide data that is ingested into the Atmos Data Store. Automated where possible using data pipelines.
4. What were the benefits of using the HSDS data service (compared with the traditional HDF5 library)?
One of the key premises for the Atmos Data Store project to work seamlessly is the ability to open NetCDF files remotely. Since the data files are often very large, it can be challenging to access and open them efficiently in a traditional file-based system. HSDS provides a cloud-based solution for remote file access, allowing engineers to open and analyze NetCDF files from anywhere with an internet connection. In other words, this enables users or applications access to the data they need quickly and efficiently, regardless of their location or the computing resources.
Another key premise is that it should be easy to set up and manage on our cloud provider’s infrastructure, which in our case is Azure. Since HSDS is Dockerized, it can easily be deployed virtually anywhere. In addition, there is a guide showing how to deploy it on Azure Kubernetes Services (AKS), which is our preferred choice for running HSDS. Running on AKS we can scale up and down as we see fit and we can deploy Kubernetes jobs to run analytics on the data without it having to leave the cloud. This has enabled us to do large scale processing, such as producing map analytics for large geographical areas (crunching 100GBs of data) in minutes with low cost.
5. Have you run into any unexpected problems/challenges during the project?
Initially, we encountered an interesting challenge in scaling up the ingestion process, specifically running multiple hsload processes concurrently. The source NetCDF data consists of collections of files that make up a single dataset, typically organized into monthly or yearly segments. To merge these individual files into a coherent domain on the HSDS server, we needed to extend the “Time” dimension. However, using the default “--extend” function only allowed for appending one file at a time at the end of the previous file. To overcome this limitation, The HDF Group implemented a new “--extend-offset” option, which enabled us to specify the exact time-index at which a given file should be placed. This allowed us to compute the corresponding time-index for each file ahead of ingestion and load multiple files concurrently, addressing the scalability challenge and facilitating efficient data ingestion.
Another challenge is to find optimal data chunking to cover all use cases. Analyzing the data over multiple dimensions (temporal, spatial) implies that a trade-off is necessary for fast slicing in all directions. Through experimentation we found that setting the chunk sizes manually on the source files worked better than letting HSDS decide the chunks for our needs.
6. How do you see HDF5/HSDS fitting in with your future plans?
Equinor sees HDF5/HSDS as a foundation for producing, managing and standardizing metocean data. The current format and HSDS solution are stable and reliable, enabling efficient storage, management, and analysis for large metocean datasets. Building on this foundation, we plan to expand the data product portfolio with more metocean data, analytics, and quality control capabilities. This allows for scaling up, enhance decision-making processes, optimize operations, and reduce risk, ultimately driving better business outcomes faster than before. Additionally, we plan to onboard more users to the Atmos Data Store platform, responding to user feedback and continuously improving the user experience. By leveraging the capabilities of the HDF5/HSDS foundation we have in place today, there are lots of potential to innovate, automate, and leverage our metocean data.
Thank you Simen, Deepthi, Serena, Susanne and Lyubov from the Atmos Data Store team! Setting up a cloud-based architecture with petabyte data storage requirements can be a challenge, but it seems like your team is well on its way. If your organization is facing similar challenges, feel free to contact us.