By John Readey
HSDS (Highly Scalable Data Service) is available and fully functional on Azure. Try HSDS out on the Azure Marketplace today!
Abstract
HSDS (Highly Scalable Data Service) is a cloud-native data service designed to fully support the HDF5 data model and API while taking advantage of cloud-based features such as object storage and on-demand compute. HSDS is an open-source, Apache2 licensed product which has been used by many organizations to provide access to HDF data over the web. Originally designed with Amazon’s AWS as the target platform, The HDF Group has worked with Microsoft Azure to enable HSDS to run equally well on Azure. Enhancements made to HSDS include: support for Azure Blob Storage, authentication with Azure Active Directory, deployment scripts for AKS (Azure Kubernetes Service), and an Azure Marketplace offer to simplify deployment. This article will discuss the design, development, and features added to HSDS for Azure.
Intro
HSDS (Highly Scalable Data Service) is a REST based service for HDF data, part of HDF Cloud, our set of solutions for cloud deployments. In the recent blog about the latest release of HSDS we discussed many of the new features in the 0.6 release including support for Azure.
The cloud landscape if highly competitive and evolving. AWS, Azure, and Google Cloud are the three recognized leaders, with many others also offering solutions as well. Feature and price-wise was the “big three” are very similar, and history has shown that whenever one of the three comes out with a new capability, the other two will quickly race to offer similar features on their platform.
At The HDF Group, we would like to see HDF flourish everywhere, so we endeavor to help users regardless of their platform choice. HSDS is designed to support new platforms with minimal changes.
In enabling HSDS on Azure the two biggest challenges are supporting Azure Blob Storage (Microsoft’s solution for object storage), and Azure Active Directory (Microsoft’s identity service) and we’ll discuss each of these in turn.
In this blog we’ll dive a bit more deeply into how support for Azure was implemented, and discuss some of our future plans for HSDS on Azure.
Azure Blob Storage
Object storage solutions have become the preferred mechanism for storing large quantities of data in the cloud. While there are various POSIX based solutions for both Azure and AWS, only object storage provides the low cost per GB, and high availability needed for large repositories.
For AWS, S3 (Simple Storage Service) has been the standard object storage service. In S3 objects (the data being stored) are organized into “buckets” where they can be retrieved by a “key” (a unique identifier to the object). Objects can be read either in their entirety, or a subset of the object can be read by providing a start and end range. When writing, the entire object must be updated.
Azure Blob Storage is similar though the terminology is different – collections are called “Containers” rather than “Buckets” and the contents are called “Blobs” rather than “Objects”. In addition, while for S3 the bucket name must be globally unique, for Azure Blob storage, containers are organized under accounts.
Azure Blobs
| Account | Container | Blob |
| ————— | ———- | ——- |
| Acme.Production | Simulation | Run1.h5 |
| | | Run2.h5 |
| Acme.Devopment | Simulation | Run1.h5 |
| | | Run2.h5 |
S3 Objects
| Bucket | Object |
| ————————— | ——- |
| Acme.Production.Simulation | Run1.h5 |
| | Run2.h5 |
| Acme.Development.Simulation | Run1.h5 |
| | Run1.h5 |
S3 Hierarchy vs Azure Hierarchy
So while any S3 object can be referred to by a combination of bucket and Key, an Azure Blob requires Account + Container + Blob (an additional level). The Azure approach is handy if, say, you want to run an application in a test account and then deploy to a production account without having to change how blobs are referenced in the code.
At a low-level, Azure supports what are known as “Blocks” which enable appending data to a blob. This feature is not used in HSDS however as we limit the size of any storage object to 2-4MB. Even though datasets in HSDS can be unlimited in size, internally we store these as smaller “chunks”, each chunk corresponding to a storage blob.
For HSDS on Azure, whenever a “bucket” parameter is given in the API, it will actually refer to a container name. The Account name that a container lives in is set in the server configuration (i.e. HSDS runs in a specific Azure account and assumes a path like: “Simulation/Run1.h5” refers to container “Simulation” in that account).
To access Azure Blobs within HSDS, we use the azure-storage-blob Python package. One critical feature that was needed for HSDS to work with Azure Blobs is async support, which fortunately Microsoft has just recently added to their azure-storage-blob package. Asynchronous processing allows HSDS to request a read or write to a blob and then perform other useful work while waiting on a response. Since each request to the Blob storage service has fairly high latency (compared say to access a local disk), this greatly improves performance. For example, to read a hyperslab selection in a HDF dataset that intersects with 16 chunks, 16 requests from HSDS to the storage service can be sent at once, rather than having to request each chunk from the storage service serially. This enables HSDS to achieve quite high throughput from the Azure storage system.
While Azure Blobs and S3 objects have different naming conventions and are accessed by different APIs, it’s worth bearing in mind that these differences are abstracted by the service. The HSDS REST API is same in either case and applications won’t need any code changes to use HSDS on Azure compared with HSDS on AWS.
Azure Active Directory
Many organizations using Azure are also utilize Active Directory for identity and access management. As a REST service, it’s important that HSDS provides a mechanism for authentication and authorization. As discussed in the blog, To Serve and Protect: Web Security for HDF5, HSDS was first developed using a authentication scheme known as “HTTP Basic Auth”.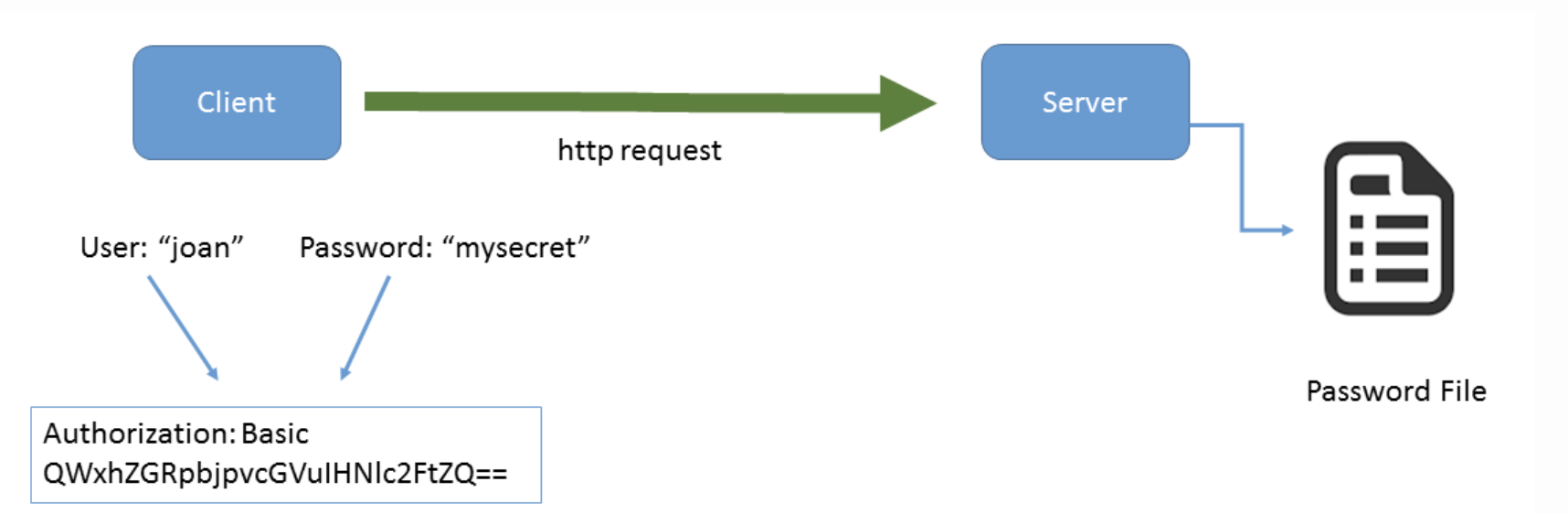
In HTTP basic auth, the requestor encodes a username and password into the Authorization header of each request. Upon receipt by the server, the username and password are decoded and then checked against a password file maintained by the server.
While this is a workable system, it can be problematic in a couple of ways.
First from a security perspective, if any request between the. client and server could be intercepted, a bad actor could use the authorization code to impersonate the client. (This is why it’s important to use HTTPS endpoints).
Secondly, there’s an administrative burden when someone has to keep the password file on the server updated for new users, rotate passwords, disable users who should no longer have access, etc.
Azure Active Directory (AAD) integration is an optional feature for HSDS that resolves these two issues. When using AAD, clients will connect with the AAD service to authenticate the user. Typically interactive users will be prompted to go to a web page to enter their login id and password. Once AAD authenticates the user’s identity it returns what is known as a “Bearer Token” – a long hexadecimal string – that the application passes to HSDS. On the HSDS side, the bearer token can be decoded to reveal the caller’s username. HSDS does not need to keep a list of usernames and passwords, and the user’s password is never exposed to the server.
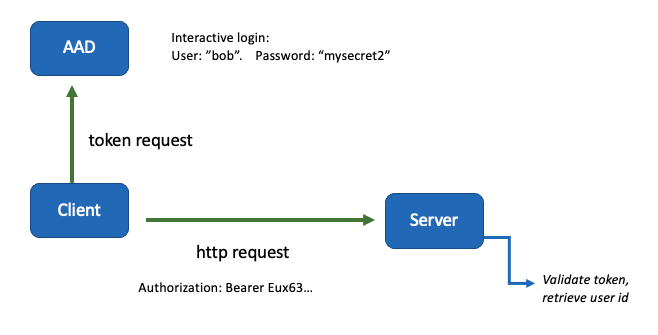
What about the security concern we had with HTTP Basic Auth, where a malicious application could use the bearer token to impersonate the user? This is less of a concern with AAD authentication — for one, Bearer tokens have a limited lifetime (typically 60 minutes), after which they need to be renewed by AAD. Also, the token can only be used by HSDS (HSDS and the app share a specific client id), so there’s no danger that a malware could use the token to access other applications.
Once HSDS has verified the Bearer token and reliably identified the user identity, the requested action (e.g. modify a file) still needs to be authorized. This part works the same as with HTTP Basic auth. The user name is compared with a list of ACLs maintained in the storage system to see if the action is permitted (see https://github.com/HDFGroup/hsds/blob/master/docs/authorization.md).
What if you need an application (say running on a remote machine) to communicate with HSDS where there is no human available to enter a username and password? In this case you can create a “client secret” in AAD for that application. If the secret is used, there will be no interactive login needed. See the “Unattended Authentication“section for detailed instructions.
Lastly, it is worth noting that HSDS doesn’t need to be running on Azure to take advantage of AAD. Whether you have HSDS running on Azure or on-prem, you can still configure the service to use AAD for authentication.
Deploying HSDS on Azure with Docker
Other than the mechanics of creating an Azure Blob storage container and creating a Virtual Machine on Azure, running HSDS on Docker in Azure works much like with AWS. The same container image files available from the HDFGroup repository on Docker Hub are used for both AWS and Azure. HSDS deduces which environment it is running in based on the presence or absence of specific environment variables (e.g. if it sees AZURE_CONNECTION_STRING, the server will expect to talk with an Azure Blob Storage container). Specific instructions for setting up HSDS on Azure with Docker can be found here.
One nice feature of the HSDS install guide for Azure is that the entire installation process (resource group and container creation, virtual machine setup, etc.) can be done using the command line using the azure-cli tools (creation of these resources is supported using the Azure Portal as well of course).
Deploying HSDS on Azure with AKS
HSDS runs as a set of containers where increasing the number containers enables more clients to be supported as well as increased parallelization for individual clients. When the number of containers you desire to run exceeds the capacity of an individual VM, you can run HSDS on Kubernetes. Kubernetes manages container based applications over a cluster of machines, making it easy to run large container workloads.
Although it’s possible to setup a Kubernetes cluster manually, it makes sense to take advantage of the managed Kubernetes offerings that Azure and AWS provide. On Azure, this is known as Azure Kubernetes Service – AKS. With AKS, setting up a cluster can be done in a few minutes using the Azure Service portal. Once the cluster is setup you can change the number of machines in the cluster as needed.
Deploying HSDS to your AKS cluster is very straightforward using the deployment yaml provided and the standard kubectl tool: `$ kubectl apply -f k8s_deployment_azure.yml` . The same kubectl can be used to scale up or down the number of HSDS pods (Kubernetes-speak for the minimal deployable unit) as needed: `$kubectl scale –replicas=n deployment/hsds`. Full instructions are here.
Now that you have an AKS cluster running with HSDS, you might want to consider adopting your favorite HDF applications to run on the cluster as well. Many application workloads that don’t require tight synchronization are good candidates for running as a set of Kubernetes pods. For example, to process a large set of data you can simply scale up the number of pods as needed (you’ll need a mechanism to distribute work among the pods). While HSDS can be accessed from inside or outside the cluster, the performance is generally better with applications running in the cluster (thus avoiding some of the overhead that external endpoints require).
REST VOL and h5pyd
For C/C++ clients, the HDF REST VOL library plugin enables the HDF5 API to read and write data using HSDS (requires v1.12.0 or greater version of the HDF5 library). Similarly, h5pyd provides a (mostly) h5py-compatible interface to the server for Python clients.
For the most part, clients that access HSDS will work the same on Azure as on AWS (or running on your desktop for that matter). An HSDS client connecting to HSDS running on Azure doesn’t need to know anything about the Azure account, or how HSDS is configured. For example, the HSDS command line tools (hsinfo, hsls, hsload, etc.) “just work” with HSDS on Azure.
For HSDS using AAD, there are some configuration changes needed for the client to use AAD authentication though. While for HTTP Basic Auth, the client needs to be configured with server endpoint, username, and password (these can be passed in as environment variables: HS_ENDPOINT, HS_USERNAME, HS_PASSWORD respectively), for AAD these environment variables (or equivalent settings in the .hscfg file) need to be set:
- HS_ENDPOINT – http endpoint of the server
2. HS_AD_APP_ID – HSDS Client Application ID – configured in AAD
3. HS_AD_TENANT_ID – AAD Tenant ID
4. HS_AD_RESOURCE_ID – HSDS Server ID – configured in AAD
See the “Client Configuration” section for details in setting these up.
Once these settings are configured, both h5pyd (for Python applications) and REST VOL (for C/C++ applications) will utilize them for using AAD Authentication.
One thing to know is that you can share the .hscfg file with anyone since it doesn’t contain any secrets.
Future Directions
The worked done so far has just scratched the surface of the different capabilities of the Azure platform. Here are a few different ideas we are currently exploring to further enhance HSDS on Azure.
Support for AAD Groups
Another new feature in the HSDS 0.6 is support for Role Based Access Control (RBAC). RBAC allows permissions on a file to be set at the group level in addition to individual user names. Currently user group membership has to be defined in a text file on the server. Since AAD can be use to manage user groups, it would be very nice to utilize AAD groups and not require groups to be set on the server.
.Net Clients
The .Net language is quite popular (particular on Azure) and it’s likely that there many people who would like to use C# (or other .Net language) to talk with HSDS running on Azure. Our colleague Gerd Heber wrote about using .Net with HDF in this blog post and thanks to his efforts we are know able to support basic HDF5 usage on .Net via HDF.PInvoke. Unfortunately, not all the HDF5 API functions needed by the REST VOL are supported in the current HDF.PInvoke release, so an update will be needed to use .Net with the HDF Rest VOL.
Another interesting possibility would be a .Net equivalent to the h5pyd Python package. H5pyd enables a high-level interaction with HSDS but doesn’t require the HDF5 library be installed (i.e. it’s a “Pure Python” application). Similarly, you could imagine a .Net library that interfaces with the HDF REST Api without the need for the REST VOL. This approach would also provide a means to work with HSDS features (e.g. dataset SQL-like queries) that are not available using the HDF5 API.
VFD Driver for Azure Blob Containers
While not strictly related to HSDS, the S3 VFD provides a useful capacity to read HDF5 files stored as S3 objects. Similarly, it would be nice to be able to read HDF5 files stored as blobs. A potential “Blob VFD” would work much the same as the S3 VFD but utilize the Blob storage API to fetch data from the HDF5 file.
Azure does support the ability to mount a container as a filesystem and this could be used for reading HDF5 files (though it requires of system configuration).
Azure Marketplace
Similar to our current AWS Marketplace offering, we are planning to make available a VM-based offering of HSDS on the Azure Marketplace. The marketplace offer will enable easy installation of HSDS on Azure.
Azure Functions
The HSDS 0.6 release also adds the ability to use AWS Lambda. AWS Lambda enables the provision of “server-less functions”, i.e. rather than providing a server that runs code, you just provide a function to AWS and Amazon runs it for you. This not only removes the need to configure systems but provides the ultimate in “elasticity” – you can scale up as much as you need whenever you need and only get billed for the number of CPU seconds your function consumes.
Azure has a similar (but different) capability called “Azure Functions”. It would be very desirable to support HSDS on Azure functions as well. Both AWS Lambda and Azure Functions are rapidly evolving, so pinning down what exactly is required will need some further investigation.
Conclusion
HSDS has made the jump from AWS to Azure with no compromises and even some new features (such as identity support using Active Directory). If you are currently using (or planning to use) Azure, we’d love you to try out HSDS on Azure and let us know how it works for you. If any of the items mentioned under “Future Directions” are of particular interest (or something else we haven’t thought of), let us know as well.
We would like to thank the Microsoft team for their support and help–enabling us to quickly and easily add support for Azure to our platform.