Hadi Salimi, Inria Rennes Bretagne – Atlantique Research Center, Matthieu Dorier, Argonne National Laboratories, and Gabriel Antoniu, Inria Rennes Bretagne – Atlantique Research Center
Project website: https://project.inria.fr/damaris/
1. Introduction
Supercomputers are expected to reach Exascale by 2021. With millions of cores grouped in massively multi-core nodes, such machines are capable of running scientific simulations at scales and speeds never achieved before, benefiting domains such as computational fluid dynamics (CFD), biology and geophysics. These simulations usually store the produced datasets in standard formats such as HDF5 or NetCDF using corresponding software libraries. To this aim, two different approaches are traditionally employed by these libraries: file-per-process and collective I/O. In the file-per-process approach, each computing core creates its file at the end of each simulation iteration. However, this approach cannot scale up to thousands of cores because creating and updating thousands of files at the end of each iteration leads to poor performance. On the other hand, collective I/O is based on the coordination of processes to write on a single file, that is also expensive in terms of performance.
Damaris[1] was first developed to address the aforementioned I/O problems. It originated in our collaboration with the JLESC – Joint Laboratory for Extreme-Scale Computing, and was the first software resulted from this joint lab validated in 2011 for integration to the Blue Waters supercomputer project. It scaled up to 16,000 cores on Oak Ridge’s leadership supercomputer Titan (first in the Top500 supercomputer list in 2013) before being validated on other top supercomputers.
In the Damaris approach, the computing resources are partitioned such that a subset of cores in each node or a subset of nodes of the underlying platform are dedicated to data management. The data generated by the simulation processes are transferred to these dedicated cores/nodes either through shared memory (in the case of dedicated cores) or through the MPI calls (in the case of dedicated nodes) and can be processed asynchronously. Afterwards, the processed data can be stored (in HDF5 format) or visualized (by VisIt) using out-of-the-box Damaris plug-ins. Damaris benefits from an external XML configuration file to define simulation data such as different parameters, data structures, mesh types, and storage backends. Using this XML file, simulation developers can easily change different parameters without changing the simulation code.
The benefits of using Damaris for storing simulation results into HDF5 is threefold: firstly, Damaris aggregates data from different processes in one process, as a result, the number of I/O writers is decreased; secondly, the write phase becomes entirely asynchronous, so the simulation processes do not have to wait for the write phase to be completed; and finally, the Damaris API is much more straightforward for simulation developers. Hence it can be easily integrated in simulation codes and easily maintained as well. By overlapping I/O with computation and by aggregating data into large files while avoiding synchronization between cores, using Damaris leads to a set of essential achievements[2]: 1) it entirely hides jitter as well as all I/O-related costs, which makes simulation performance predictable; 2) it increases the sustained write throughput compared with standard approaches; 3) it allows almost perfect scalability of the simulation up to over thousands of cores.
2. Using Damaris
In this section, we briefly demonstrate how Damaris can be employed by Simulation developers to instrument an existing simulation.
2.1 Data Description
The first step in using Damaris is to define simulation data using an XML file. Then, to write simulation data into the HDF5 format, it is necessary to define the simulation variables and their layout in the XML file first. As the below excerpt shows, a variable, namely temperature, has been defined in the XML file to be written to disk. The layout of this variable is defined as my_layout, as its definition can be found below as well. As shown, my_layout is a 2D grid containing double values. The two dimensions of this grid are parametrized using two parameters, X and Y.
<parameter name="size" type="int" value="100" />
<parameter name="X" type="int" value="10000" />
<parameter name="Y" type="int" value="1000" />
<layout name="my_layout" type="double" dimensions="X/size,Y" global="X,Y"/>
<variable name="temperature" layout="my_layout" store="my_store"/>
In the definition of my_layout, two dimensions have been introduced, using dimensions and global attributes. The dimensions attribute represents the dimensions of the grid that is held by each process locally. The global attribute is used for determining the global dimensions of the variable across all processes. These two attributes are used by Damaris’ HDF5 plug-in to write simulation data in different working modes, i.e., file-per-core or collective I/O. Also, while defining a variable, the simulation developer should determine the storage backend that is used for storing the variable. In the above example, the temperature variable uses the my_store storage backend that is defined in the same XML file as shown below:
<storage>
<store name="my_store" type="HDF5">
<option key="FileMode">FilePerCore</option>
<option key="FilesPath">/opt/simu/data/</option>
</store>
</storage>As depicted, the storage backends are introduced inside a <storage> tag. Given the fact that different storage backends may be supported by Damaris later, each backend is defined inside another inner tag, called <store>. For now, to store simulation datasets into HDF5, the type of the introduced store should be HDF5. In addition, the FileMode attribute determines how Damaris should store data (either FilePerCore or Collective). The location of the stored files could be determined using the FilesPath attribute.
2.2 Instrumentation
To instrument a simulation with Damaris, the first step is to initialize and start it. Also, at the end, Damaris should be stopped and finalized. Since Damaris is developed on top of MPI, it should be initialized after MPI and finalized before MPI. When starting Damaris using damaris_start, an argument is returned (is_client in the code) indicating whether the process is a client process (runs the simulation) or a server process (aggregates data on dedicated cores). Based on the returned value of this argument, Damaris either runs the main simulation loop (client mode) or is blocked for receiving simulation data from clients.
int X,Y;
int main ( int argc , char argv ) {
MPI_Init (&argc , &argv ) ;
err = damaris_initialize("config.xml" , MPI_COMM_WORLD) ;
double *grid;
Int is_client size, rank;
MPI_Comm global;
damaris_start(&is_client) ;
if (is_client) {
damaris_client_comm_get (&global) ;
damaris_parameter_get("X" , &X , sizeof(int));
damaris_parameter_get("Y" , &Y , sizeof(int));
MPI_Comm_rank(comm , &rank);
MPI_Comm_size(comm , &size);
grid = malloc((X/size)*Y*sizeof(double));
// initialize grid for the first time
sim_main_loop(global , grid , size , rank);
damaris_stop();
}
damaris_finalize() ;
MPI_Finalize();
return 0;
}In addition to the API shown above, other functions in Damaris can be used for reading the parameters defined in XML file. Here, damaris_parameter_get has been used to retrieve the value of X and Y parameters. A similar method, damaris_parameter_set, can be used for setting the value of parameters from simulation code.
void sim_main_loop (MPI_Comm comm, double* grid, int size, int rank) {
int i ;
int64_t position[2];
position[0] = rank*(X/size);
position[1] = 0;
for ( i =0; i<100; i++) {
// do something using comm as global communicator
// and update the grid accordingly
damaris_set_position("temperature", position);
damaris_write("temperature", grid)
damaris_end_iteration();
}
}
The above function, sim_main_loop shows how data can be passed to Damaris. As demonstrated, to benefit from the Damaris HDF5 backend, the first step is to pass Damaris the exact grid location that the process is working on. This information is passed to Damaris by calling damaris_set_position method with the variable name as the first parameter and the position array as the second parameter. Afterwards, the pointer to the real data should be passed to Damaris using damaris_write. This method takes the variable name as its first argument and the pointer to local data as the second argument. Finally, by calling damaris_end_iteration method, the simulation confirms that all of the needed data has been passed to Damaris for this iteration.
2.3 Configuration
Other XML attributes can be changed as well to configure the working parameters of Damaris. For example, by updating this XML file, it is possible to change the number of dedicated cores, dedicated nodes, VisIt connection parameters, mesh definitions, logging capabilities and so on. For more information about configuring these parameters take a look at the online documentation on the Damaris homepage.
3. Performance Evaluation
To evaluate the effectiveness of using Damaris for writing simulation data into HDF5, we have carried out several experiments. In these experiments, we have used an extended version of the 3dMesh proxy application. 3dMesh is developed as a simple tool for verification of Damaris HDF5 backed. This proxy application follows the typical behavior of a scientific simulation which alternates computation and I/O phases. The domain of 3dMesh, as the name implies, is a fixed 3D grid with each of its internal points characterized as a floating point value. 3dMesh is written in C and parallelization is done using MPI, by decomposing the main domain into a set of smaller grids that are handled by each process.
During the experiments, we used 70 nodes of the paravance cluster of Grid’5000, (featuring 72 nodes of 2 Intel Xeon 2.4 GHz CPUs, 8 cores/CPU, 128GB of RAM) to run the 3dMesh proxy application. The nodes inside this cluster communicate over a 10 Gbps network. In this cluster, we deployed a PVFS file system on 6 nodes, used both as storage and metadata servers. We used the rest of the cluster resources as computing nodes.
We carried out the experiments in three different steps: 1) with 256 cores 2) with 512 cores and 3) with 1024 cores. We used a domain size of 25600x100x100, 51200x100x100, and 102400x100x100 for the mentioned steps, respectively. This means that in all of the experiments, each core processes a 100x100x100 grid. In addition, in each step, we configured Damaris to write the data using four different working modes. The name and configuration of each working mode are described in the table below:
| Ref. | Working Mode | Dedicated Cores/Node |
Simulation Cores/Node |
File Creation Mode | Write Mode |
| 1. | File-per-process | 0 | 16 | Each process writes on its own file. | Synch. |
| 2. | Collective | 0 | 16 | All processes write to the same file. | Synch. |
| 3. | File-per-dedicated-core | 1 | 15 | Each dedicated core writes on its own file | Asynch. |
| 4. | Collective-from- dedicated-cores | 1 | 15 | All dedicated cores write to the same file | Asynch. |
3.1 Simulation write time
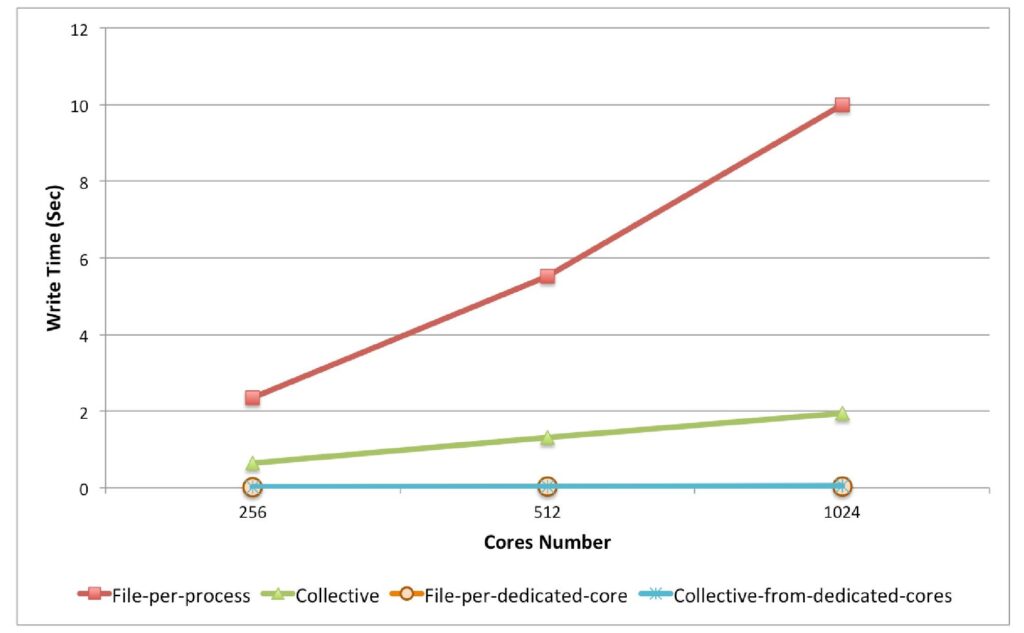
During the first set of experiments, we measured the average time of write phase from the simulation’s point of view. In other words, we measured how long the simulation is blocked in average between every two iterations. As measured results show in the below Figure, the time is very high for the file-per-process case, reaching up to 9.9 seconds on 1024 cores. This long write time was predictable due to the nature of file-per-process writing mechanism, that should create lots of files at each iteration. This write time is lower for the collective case because in this case there is no need to create and update lots of files in each iteration.
When using Damaris in asynchronous mode, we dedicated one core (out of 16) for data management. These dedicated cores could write the aggregated data in two different modes: file-per-dedicated-core and collective-from-dedicated-cores. In the former case, all of the dedicated cores write their data on separate files, while in the latter case, all of the dedicated cores write them on the same file. As depicted in below figure, the time to write data from the point of view of the simulation is decreased to the time required to perform a series of copies in shared memory. It leads to an ignorable write time of 0.03 seconds and does not depend anymore on the number of processes.
 3.2 Simulation run-time
3.2 Simulation run-time
In the next set of experiments, we measured the simulation run time for 200 iterations including 10 write phases. Like the previous experiment, we ran the 3dMesh proxy application on 256, 512 and 1024 cores and measured the execution time of the simulation on the same four configurations. The results of these experiments are depicted in the figure below.
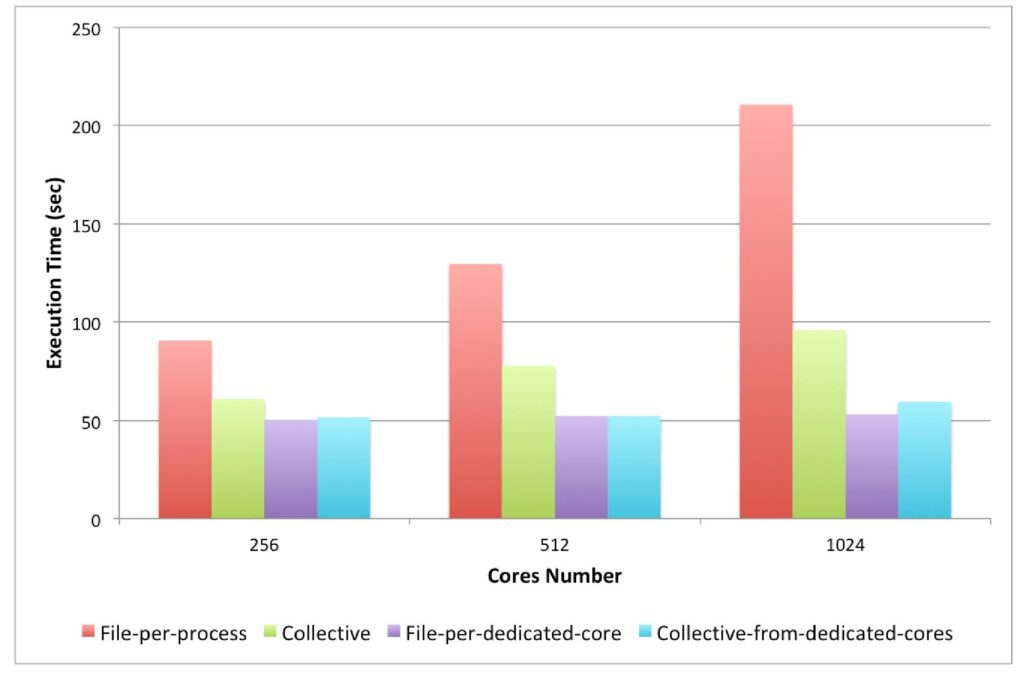 As the above Figure shows, although leaving one core for I/O management does not increase the execution time of the simulation, but in all cases it helps the simulation to even run faster. For example for the case of 256 and 512 cores (file-per-process mode compared to file-per-dedicated-core), Damaris has helped the simulation to run faster up to 79.8% and 148.6%, respectively. This improvement is even better for 1024 cores and reaches up to 297.1%. The main reason behind these improvements is that Damaris overlaps computation and I/O writes, as a result, if writing data takes a long time for an specific configuration, Damaris performs better on that case too. For the collective scenarios, the improvement reaches up to 18.2%, 49.2%, and 61.1% for 256, 512 and 1024 cores, respectively.
As the above Figure shows, although leaving one core for I/O management does not increase the execution time of the simulation, but in all cases it helps the simulation to even run faster. For example for the case of 256 and 512 cores (file-per-process mode compared to file-per-dedicated-core), Damaris has helped the simulation to run faster up to 79.8% and 148.6%, respectively. This improvement is even better for 1024 cores and reaches up to 297.1%. The main reason behind these improvements is that Damaris overlaps computation and I/O writes, as a result, if writing data takes a long time for an specific configuration, Damaris performs better on that case too. For the collective scenarios, the improvement reaches up to 18.2%, 49.2%, and 61.1% for 256, 512 and 1024 cores, respectively.
3.3 Code changes
In addition to the reported performance improvements, Damaris also helps simulation developers to work with a simpler API. Therefore, the number of the lines added to the simulation code to support HDF5 is decreased. In addition, moving the data description parts out of the source code makes the data definition easier and simpler.
The table below summarizes the number of lines of code required to instrument the 3dMesh proxy application with HDF5 and with Damaris. As this table shows, for supporting HDF5 into the 3dMesh application, it was required to add 64 lines of code. But with Damaris, it was around 14 lines of code and 30 lines of XML configuration file. Moreover, it should be noted that the changes made in the simulation for supporting HDF5 can be used for writing data to other data formats (e.g., NetCDF) or in situ processing tasks as well.
| Simulation | Pure HDF5 | Damaris | |
| C | C | XML | |
| 3dMesh.c | 64 lines | 14 lines | 30 |
4. In Situ Processing
In traditional simulations, datasets resulting from the simulation are typically shipped to some auxiliary post-processing platforms for visualization and further analysis, that is very costly in terms of storage space, transfers, and performance. In addition, no scientifically usable result is available before the end of the post-processing phase. To resolve these issues, the high-performance computing (HPC) community has shown considerable interest in “in situ” processing, that is, visualization and analysis of simulation data while the simulation is still running. The most important reasons in favor of in situ processing are: 1) Reducing the I/O costs by not writing the results first on disk and then loading them back in memory; 2) Providing the potential to use all available resources (e.g. GPUs) in the supercomputer that runs the simulation; 3) Providing support for computational steering of the simulation by allowing users to change the input configuration at run-time.
Although Damaris was first proposed to tackle the I/O challenges of large-scale simulations, over the years it has evolved into a more elaborate system, providing the possibility to use dedicated cores or dedicated nodes in support of in situ and in transit data analysis and visualization. The current version of Damaris offers a seamless connection to the VisIt visualization framework to enable in situ visualization[3] with minimum impact on the simulation code and its runtime. In addition, by supporting different kinds of plug-ins, it would be possible for the simulation developers to write their own in situ tasks and introduce them to Damaris using the XML configuration file. The introduced in situ tasks will be executed on Damaris dedicated cores/nodes and will analyze the simulation data while the simulation is still running.
5. Future Plans
HDF5 version 1.10.1 comes with a new feature called Virtual Dataset (VDS). This feature enables HDF5 developers to access and work with data stored in a collection of HDF5 files (such as the ones stored by different cores in the case of Damaris) as if the data is stored in a single .h5 file. This feature is not supported in Damaris yet, because the .vds files cannot be created collectively in the version of HDF5 (1.10.1) that is supported by Damaris. However, this issue is expected to be addressed in the 1.10.3 HDF5 release. As a future plan, Damaris will support VDS files in the file-per-dedicated-core case. This means that using this VDS file, the whole files created by dedicated cores could be accessed like a single HDF5 file created in collective mode. Building XDMF files for the generated HDF5 files is a future plan as well.
Acknowledgement
Experiments presented in this post were carried out using the Grid’5000 testbed, supported by a scientific interest group hosted by Inria and including CNRS, RENATER and several Universities as well as other organizations (see https://www.grid5000.fr).
References
[1] M. Dorier, G. Antoniu, F. Cappello, M. Snir, L. Orf. “Damaris: How to Efficiently Leverage Multicore Parallelism to Achieve Scalable, Jitter-free I/O”, In Proc. of IEEE CLUSTER – International Conference on Cluster Computing, Sep 2012, Beijing, China. URL: https://hal.inria.fr/hal-00715252
[2] M. Dorier, G. Antoniu, F. Cappello, M. Snir, R. Sisneros, O. Yildiz, S. Ibrahim, T. Peterka, L. Orf, “Damaris: Addressing Performance Variability in Data Management for Post-Petascale Simulations”, ACM Transactions on Parallel Computing (ToPC), Vol. 3, No. 3, December 2016. URL: https://hal.inria.fr/hal-01353890
[3] M. Dorier, R. Sisneros, T. Peterka, G. Antoniu, D. Semeraro, “Damaris/Viz: a Nonintrusive, Adaptable and User-Friendly In Situ Visualization Framework,”, in Proc. of IEEE LDAV – International Conference on Large Data Analysis and Visualization, October 2013, Atlanta, GA, USA. URL: http://hal.inria.fr/hal-00859603