Elena Pourmal and Larry Knox, The HDF Group
Internal compression is one of several powerful HDF5 features that distinguish HDF5 from other binary formats and make it very attractive for storing and organizing data. Internal HDF5 compression saves storage space and I/O bandwidth and allows efficient partial access to data. Chunk storage must be used when HDF5 compression is enabled.
In an earlier blog, HDF5 Data Compression Demystified #1, we discussed the proper use of compression filters, and presented a few troubleshooting techniques. In this blog, we’ll discuss performance tuning—certain combinations of compression, chunked storage and access pattern may cause I/O performance degradation if used inappropriately. The HDF5 Library provides tuning parameters to achieve I/O performance comparable with the I/O performance on raw data that uses contiguous storage.
Compression and Chunk Storage
One of the most powerful features of HDF5 is its ability to store and modify compressed data. The HDF5 Library comes with two pre-defined compression methods, GNUzip (Gzip) and Szip and has the capability of using third-party compression methods as well. The variety of available compression methods means users can choose the compression method that is best suited for achieving the desired balance between the CPU time needed to compress or un-compress data and storage performance.
As mentioned above, chunk storage must be used when HDF5 compression is enabled. Compressed data is stored in a data array of an HDF5 dataset using a chunked storage mechanism. The data array is split into equally sized chunks each of which is stored separately in the file.
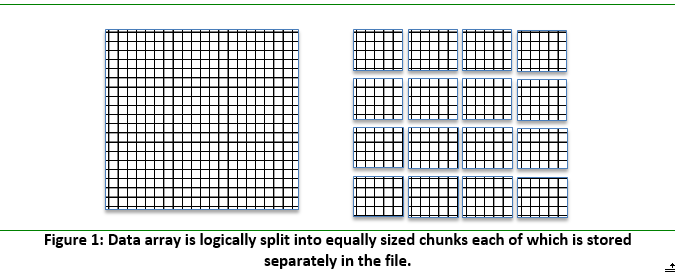
Compression is applied to each individual chunk. When an I/O operation is performed on a subset of the data array, only chunks that include data from the subset participate in I/O and need to be uncompressed or compressed.
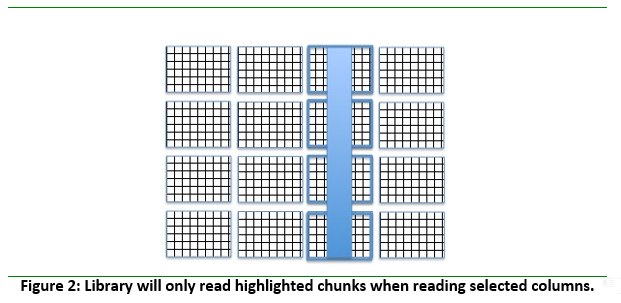 Chunked storage also enables adding more data to a dataset without rewriting the whole dataset. Figure 3 below shows more rows and columns added to a data array stored in HDF5 by writing highlighted chunks that contain new data.
Chunked storage also enables adding more data to a dataset without rewriting the whole dataset. Figure 3 below shows more rows and columns added to a data array stored in HDF5 by writing highlighted chunks that contain new data.
 While HDF5 chunked storage and compression obviously provide great benefits in working with data, HDF5 users have found that sometimes I/O performance is slower for compressed data than for uncompressed data. For example, there may be a significant performance difference between an application reading compressed data and reading the same data that was not compressed. For an application that writes compressed data, I/O performance may be excellent, but when data is moved to another system and read back, I/O performance drastically drops making data virtually unusable.
While HDF5 chunked storage and compression obviously provide great benefits in working with data, HDF5 users have found that sometimes I/O performance is slower for compressed data than for uncompressed data. For example, there may be a significant performance difference between an application reading compressed data and reading the same data that was not compressed. For an application that writes compressed data, I/O performance may be excellent, but when data is moved to another system and read back, I/O performance drastically drops making data virtually unusable.
Many of these cases of drastically slower reading performance can be ameliorated. When creating datasets, careful consideration of avoiding chunking arrangements that may cause poor reading performance or a few simple changes to the application reading the data can make all the difference.
Tuning for Performance
There are several strategies one can apply to get better I/O performance. The strategies for improving performance require modifications to the reading application or to the HDF5 file itself. The reader should choose the strategies that are appropriate for a particular use case.
Adjust Chunk Cache Size
The HDF5 Library automatically creates a chunk cache for each opened chunked dataset. The first strategy is to check whether the current chunk cache settings work properly with the application access pattern and reset the chunk cache parameters as appropriate.
Default chunk cache size is set at 1 MB—HDF5 allows applications to determine the appropriate chunk cache size and strategies (for example, use H5Pset_chunk_cache instead of H5Pset_cache or disable chunk cache completely[¹] ). Chunk size may be large because it worked well when data was written, but it may not work well for reading applications. An HDF5 application will use a lot of memory when working with such files, especially if many files and datasets are open. We see this scenario very often when users work with large collections of HDF5 files (for example, NASA’s NPP satellite data; our Improving I/O Performance When Working with Compressed Datasets paper discusses one of those use cases).
Further, making chunk cache size the same as chunk size will only solve the performance problem when data that is written and read belongs to one chunk. This is not usually the case. Suppose you have a row that spans several chunks. When an application reads one row at a time, it will not only use a lot of memory because the chunk cache is now large, but there will also be a performance problem in that the same chunk will be read and discarded many times.
Two ways to deal with this performance problem are to adjust the access pattern or to have a chunk cache that contains as many chunks as possible for the I/O operation. Ideally all chunks accessed for the I/O operation will fit in the cache at the same time, and will remain there until no longer needed.
Change the Access Pattern
When changing the chunk cache size is not an option (for example, when many datasets are being accessed and machine memory is limited), one can consider a reading strategy that will minimize the effect of the chunk cache size. The strategy is to read as much data as possible in each read operation.
As we mentioned before, the HDF5 Library performs I/O on the whole chunk. The chunk is read, uncompressed, and the requested data is copied to the application buffer. If in one read call the application requests all data in a chunk, then obviously chunk caching (and chunk cache size) is irrelevant since there is no need to access the same chunk again.
Change the Chunk Size
Adjusting the chunk cache size and changing the access pattern both require making changes to the program source code. Users who cannot or choose not to make those changes may find using h5repack to create a copy of the file with a chunk size more appropriate for the access pattern will also dramatically reduce overall processing time.
Data producers should consider that users who cannot modify applications to increase the chunk cache size or to change the access pattern will not encounter a performance problem if chunks in the file are smaller than 1MB (1x9x30x717 by 4 bytes) because the whole chunk will fit into the chunk cache of the default size. Therefore, if data in the HDF5 files is intended for reading by unknown user applications or on systems that might be different from the system where it was written, it is a good idea to consider a chunk size less than 1MB. In this case applications that use default HDF5 settings will not be penalized.
Users who cannot change an access pattern that is badly matched for an existing data file may find using h5repack to create a copy of the file with a chunk size more appropriate for the access pattern will save overall processing time.
Performance Tuning Example
This example from Improving I/O Performance When Working with Compressed Datasets demonstrates the effect of the three strategies on the time to read a 43 MB compressed dataset with a chunk size just under 3 MB. The file is an aggregation of 15 Cross-track Infrared Sounder (CriS) granules. While the examples focus on reading only, the same approach will work for writing, too.
When compression is enabled for an HDF5 dataset, the library must always read an entire chunk for each call to H5Dread unless the chunk is already in the cache. To avoid a situation where the cache is not used, make sure that the chunk cache size is big enough to hold the whole chunk, or that the application reads the whole chunk in one read operation, bypassing the chunk cache.
When experiencing I/O performance problems with compressed data, find the size of the chunk and try the strategy that is most applicable to your use case:
- Increase the size of the chunk cache to hold the whole chunk.
- Increase the amount of the selected data to read (making selection to be the whole chunk will guarantee bypassing the chunk cache).
- Decrease the chunk size by using the
h5repacktool to better match the access pattern and to fit into the default size chunk cache.
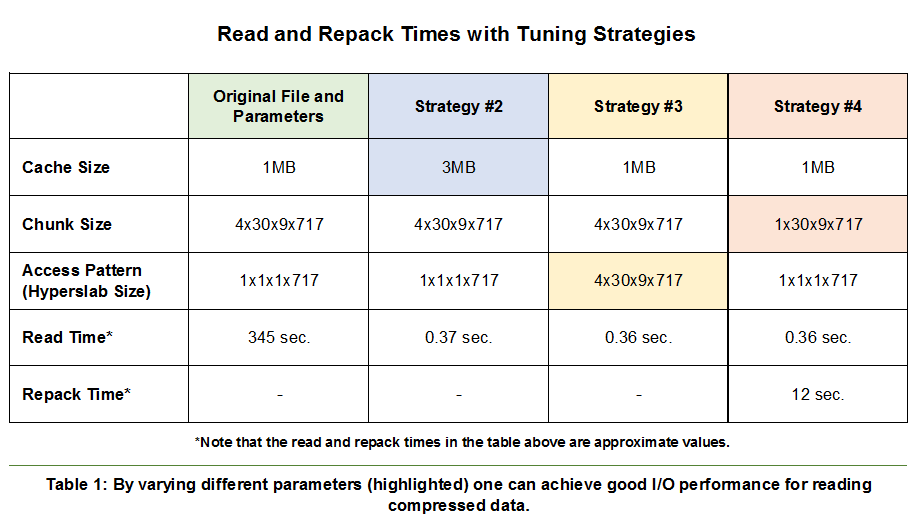
The results of all three strategies provide similar read performance and are summarized in Table 1 below. The original access pattern read a hyperslab along the 4th dimension. This resulted in 1080 accesses to read the 4x30x9x717 chunk, and decompressing the entire nearly 3 MB chunk for each of the 1080 accesses (Column 1). The time required for those repeated decompressions was nearly 6 minutes. Since the cache size was too small to hold a chunk, in effect there was no caching of the decompressed chunk.
The second strategy increased the chunk cache size to 3MB, large enough to hold the entire chunk reduced the time required for the 1080 accesses to 0.37 seconds, since the entire chunk was available in memory and needed decompression only once.
The third strategy changed the program code to read an entire chunk into memory, decompressing it once, and accessing the data from the buffer in memory.
The fourth strategy read data in the file using the original access pattern and default cache size but with the file’s dataset pre-processed with h5repack into chunks matching the size of the hyperslab to be read. The 12 seconds to repack the file, changing the chunk size in the dataset to be read, was much less than the original read time.
Repacking a file to remove compression or change chunk dimensions
Please note that when chunks are stored without compression, the library’s behavior depends on the cache size relative to the chunk size. If the chunk fits the cache, the library reads the entire chunk for each call to H5Dread unless it is in the cache already. If the chunk doesn’t fit the cache, the library reads only the data that is selected directly from the file. There will be more read operations, especially if the read plane does not include the fastest changing dimension.
One can use the h5repack tool to remove compression from a dataset by using the following command:
% h5repack -f /All_Data/CrIS-SDR_All/ES_ImaginaryLW:NONE gz6_SCRIS_npp_d20140522_t0754579_e0802557_b13293__noaa_pop.h5 new.h5
The same command with different arguments can be used to change the chunk size (as was done for Strategy #4 in column 4 of the table above):
% h5repack -l /All_Data/CrIS-SDR_All/ES_ImaginaryLW:CHUNK=1x30x9x717 gz6_SCRIS_npp_d20140522_t0754579_e0802557_b13293__noaa_pop.h5 File_with_ compression-small-chunk.h5
The chunk layout may be applied to multiple datasets of the same size by using a comma-separated list in the above command:
% h5repack -l /All_Data/CrIS-SDR_All/ES_ImaginaryLW,/All_Data/CrIS-SDR_All/ES_NEdNLW, /All_Data/CrIS-SDR_All/ES_RealLW:CHUNK=1x30x9x717 gz6_SCRIS_npp_d20140522_t0754579_e0802557_b13293__noaa_pop.h5 File_with_ compression-small-chunk.h5
This h5repack command to change chunk size in 3 datasets ran in only 1 second more than the command to change 1 dataset—13 seconds rather than 12.
In our paper, Improving I/O Performance When Working with Compressed Datasets we discuss in much more detail the factors that should be considered when storing compressed data in HDF5 files and how to tune those parameters to optimize the I/O performance of an HDF5 application when working with compressed datasets. For illustration, we use an HD5 file with Cross-track Infrared Sounder (CriS) data from the Suomi NPP satellite.
Acknowledgements:
This work was supported by the National Aeronautics and Space Administration (NASA) under SGT prime contract number NNG12CR31C. Any opinions, findings, conclusions, or recommendations expressed in this material are those of the authors and do not necessarily reflect the views of NASA or SGT.
For more information on other factors affecting performance, see:
Improving I/O Performance When Working with HDF5 Compressed Datasets
“Things That Can Affect Performance” page in the FAQ on the website
HDF5 Data Compression Demystified #1 Blog
[¹] H5Pset_cache can be used to set a chunk cache size different than 1 MB for all datasets in a file if dataset sizes and access patterns are similar for all datasets and available memory is unlimited. H5Pset_chunk_cache can set a different appropriate chunk cache size for each dataset in a file or can override the global dataset chunk cache size set by H5Pset_cache for specific datasets. These functions can also be used to disable chunk cache completely by setting the chunk cache size to 0.