M. Scot Breitenfeld – The HDF Group
“Any software used in the computational sciences needs to excel in the area of high performance computing (HPC).”
 The Computational Fluid Dynamics (CFD) General Notation System (CGNS) is an effort to standardize CFD input and output data, including grid (both structured and unstructured), flow solution, connectivity, boundary conditions, and auxiliary information. It provides a general, portable, and extensible standard for the storage and retrieval of CFD analysis data. The system consists of two parts: (1) a standard format for recording the data, and (2) software that reads, writes, and modifies data in that format.
The Computational Fluid Dynamics (CFD) General Notation System (CGNS) is an effort to standardize CFD input and output data, including grid (both structured and unstructured), flow solution, connectivity, boundary conditions, and auxiliary information. It provides a general, portable, and extensible standard for the storage and retrieval of CFD analysis data. The system consists of two parts: (1) a standard format for recording the data, and (2) software that reads, writes, and modifies data in that format.
CGNS data was originally stored using a file format called ADF (‘Advanced Data Format’), but ADF does not have parallel I/O or data compression capabilities, and does not have the support base and tools that HDF5 offers. ADF has since been superseded by the Hierarchical Data Format, Version 5 (HDF5) as the official default underlying storage mechanism for CGNS.
Any software used in the computational sciences needs to excel in the area of high performance computing (HPC). In 2013, CGNS introduced parallel I/O APIs using parallel HDF5. However, the CGNS community found that the performance of the new parallel APIs was very poor in most circumstances. In 2014, NASA provided funding for The HDF Group to improve the under-performing parallel capabilities of the CGNS library. What follows is a summary of this work done by The HDF Group.
Project Highlights
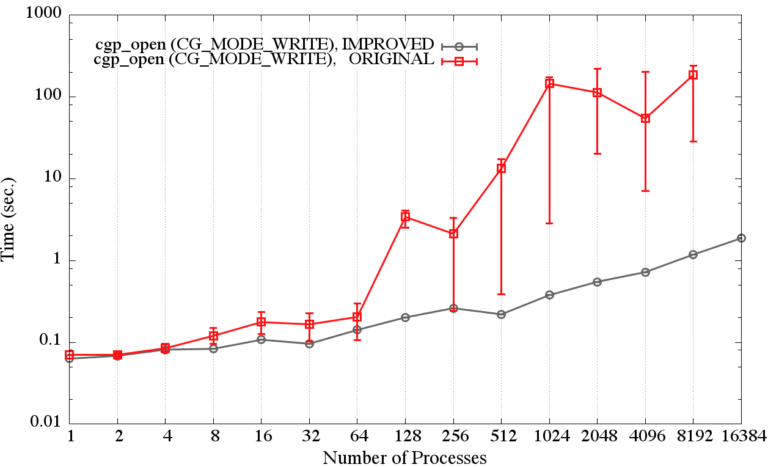
Many of the changes discussed hereafter address the underperforming parallel capabilities of the CGNS library (CGNS v3.2.1). For example, the CGNS function cgp_open, which opens a CGNS file for processing, had substantially increased execution time as the number of processes was increased, Figure 1 (original). In fact, for runs with the largest number of processes (>1024), the batch job had a time limit of 5 minutes and not all the processes had completed cgp_open before this limit was reached. Obviously, the previous implementation of cgp_open was a lot worse than reported in the figure below.
The use of collective I/O to reduce the number of independent processes accessing the file system helped to improve the metadata reads for cgp_open substantially, yielding 100-1000 times faster execution times (improved, below) over the previous implementation (original).
During the course of the project, many additional enhancements were added to CGNS to better utilize HDF5 including:
- Added support in CGNS for future release of HDF5 1.10, which was needed as a consequence of changing
hid_tfrom a 32-bit integer in HDF5 v1.8 to a 64-bit integer in HDF5 v1.10. - Added support in CGNS for using HDF5’s forthcoming multi-dataset parallel reading capability and writing multi-component datasets using a single call. The new HDF5 APIs have the benefit of packing multiple datasets into a single buffer and then having the underlying MPI I/O complete the I/O request using just one call.
The project made additional changes to CGNS, and further details can be found in the release document for the next major release of CGNS (v3.3.0) on GitHub.
Parallel Performance Results
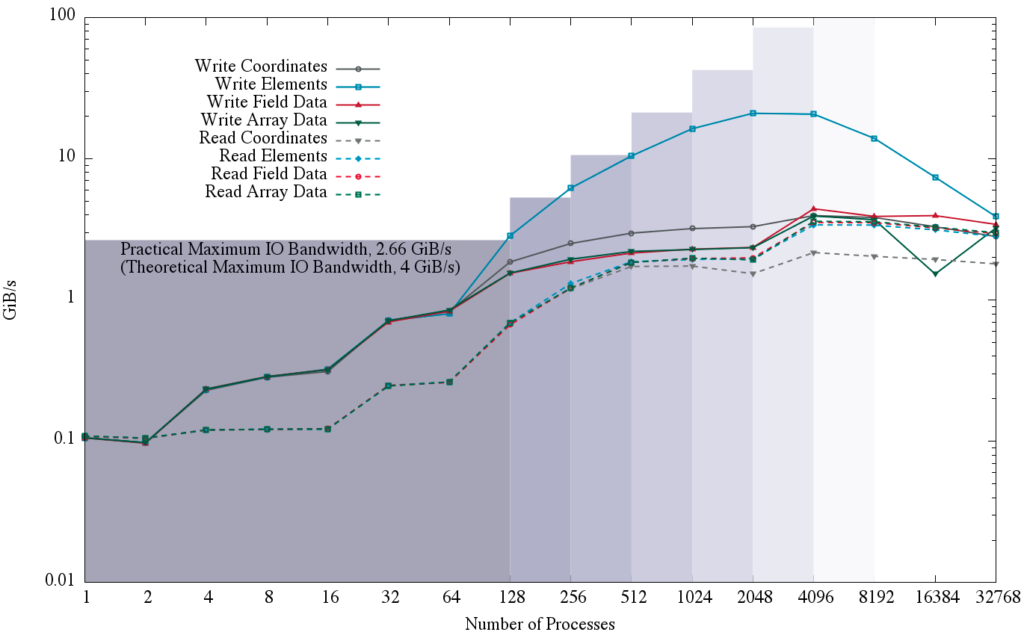
The following results are from CGNS benchmark programs created during the course of the project. The benchmarks simulate writing and then reading a ~33.5 million, 6-node pentahedra element mesh with ~201 million nodes. Figure 2 highlights just one of the available benchmarks by comparing the maximum I/O bandwidth speeds for reading and writing CGNS data compared to the practical maximum I/O bandwidth on Argonne National Laboratory (ANL’s) Cetus computer, and it shows the extremely fast writing of the element connectivity table.
The CGNS library continues to be used as a benchmark for testing HDF5’s parallel performance. Hence, The HDF Group recently addressed the poor scalability of the CGNS parallel function cgp_close, which closes a CGNS file. During the closing of the HDF5 file (via cgp_close) the current implementation of H5Fclose and H5Fflush showed poor performance as the number of processes accessing the file’s metadata cache increases. A new patch for the HDF5 library was developed which resulted in making cgp_close nearly 100 times faster on 16,384 processes, in Figure 3, below.
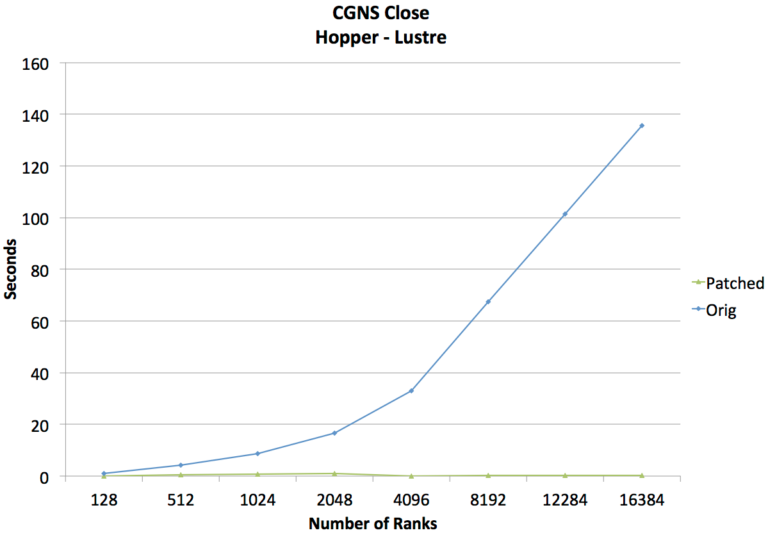
Many of these improvements are scheduled to be included in the upcoming HDF5 releases, so other applications should see similar improvements in the performance of metadata access on a large number of processes.
This project was funded by NASA through the CGNS project, contract #NNL14AB41T. Additionally, the computational studies done on Cetus and Mira at Argonne National Laboratory used allocation time through the ExaHDF5 project, DOE contract #DE-AC02-05CH11231. Computational studies on the Lustre file system were done on Pleiades through NASA’s High-End Computer Capabilities Project.