by John Readey, The HDF Group
HSDS (Highly Scalable Data Service) is described as a “containerized” service (e.g.: https://www.hdfgroup.org/solutions/highly-scalable-data-service-hsds/), but how are these containers organized to create the service? Let’s explore this a bit.
Containerization is the idea of packaging up the code and dependencies into a standard “container image” binary file that enables containers to be deployed in a uniform fashion. The analogy to shipping containers if very apt in that in the shipping industry containers enable goods to be transported from ship to rail to truck without the shipper needing to be concerned about the contents of each container. Similarly software containers enable applications to be assembled and managed without needing to know the specific libraries, configuration, files, build settings, etc of each container.
Container images are typically stored in a repository (e.g. DockerHub) that enable the images to be accessed as needed. You can find the container images for each HSDS release on Docker. The container image can be deployed using Docker, Kubernetes, DC/OS, or whatever container management systems is appropriate.
To run HSDS with Docker (probably the simplest case), a deployment YAML file specifies which containers to instantiate, the cpu and memory limits, and how the containers are linked together. This folder provides different yaml files for running on AWS, Azure, or Posix-based systems. The script will select one of these YAML files based on which environment variables it finds. E.g. if AWS_S3_GATEWAY is set, the runall.sh assumes the deployment will us S3 for storage.
If you start HSDS using runall.sh, you can see the containers that are launched using the “docker ps” command:
$ docker ps` CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES` cea65fc0c6a4 hdfgroup/hsds "/bin/bash -c /entry…" 24 seconds ago Up 22 seconds 5100-5999/tcp,0.0.0.0:58199->6101/tcp hsds_dn_4` 9656551c51bb hdfgroup/hsds "/bin/bash -c /entry…" 24 seconds ago Up 23 seconds 5100-5999/tcp, 0.0.0.0:58195->6101/tcp hsds_dn_2` 4fddd3e7182c hdfgroup/hsds "/bin/bash -c /entry…" 24 seconds ago Up 22 seconds 5100-5999/tcp, 0.0.0.0:58197->6101/tcp hsds_dn_1` d2098493fe0d hdfgroup/hsds "/bin/bash -c /entry…" 24 seconds ago Up 23 seconds 5100-5999/tcp, 0.0.0.0:58193->6101/tcp hsds_dn_3` 4da771fc37e2 hdfgroup/hsds "/bin/bash -c /entry…" 25 seconds ago Up 24 seconds 5100/tcp, 5102-5999/tcp, 0.0.0.0:5101->5101/tcp hsds_sn_1` d7b6b16e1dd8 hdfgroup/hsds "/bin/bash -c /entry…" 25 seconds ago Up 24 seconds 5100-5999/tcp, 0.0.0.0:58192->6900/tcp hsds_rangeget_1` 42e5b5538e8f hdfgroup/hsds "/bin/bash -c /entry…" 26 seconds ago Up 25 seconds 5101-5999/tcp, 0.0.0.0:58191->5100/tcp hsds_head_1`
Graphically, this looks like the following diagram.
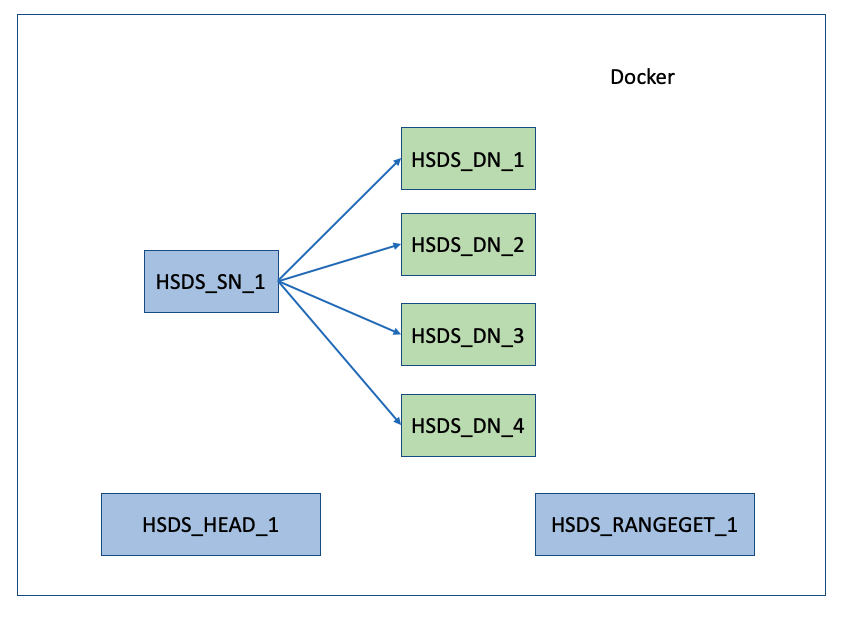
Note that there is not just one container running but (in this case at least) seven. So you may wonder: why multiple containers and what are the roles they perform? This is the question that was posed in this issue, so let’s attempt to shed some light on this.
In the output above you’ll notice the container names are: hsds_head_1, hsds_rangeget_1, hsds_sn_1, hsds_dn_1, ..., hsds_dn_4. I.e. we have a “head” container, a “rangeget” container, a “sn“, and four “dn” containers. Each of these container types have a different role to play in HSDS:
sn: these containers handle requests coming from HSDS clients. Each request is authenticated (i.e. verification of user’s credientals), authorized (verified the requested action is allowed for that user), and inspected to make sure that request parameters are valid. The actual reading or writing of data to the storage system is not performed by the SN container, but by the DN container…dn: these containers get requests from the SN containers and in turn read or write data to the storage systemhead: this container is a singleton (i.e. should only be one instance) and is used as a central checkin point by the other containers. Each SN and DN periodically sends a healthcheck request to the head container. This enables the head container to monitor the state of the other containers and keep track of the number of containers running in the servicerangeget: this container is used by the DN containers to more efficiently read chunks in HDF5 files. Like the head container, it’s a singleton. We’ll talk more about the rangeget container in a future blog post
The runall.sh script will by default create four DN containers, but you can supply an argument to specify the number of containers to desired (e.g. runall.sh 1 will create one DN container, runall.sh 8, will create eight DNs, etc.). Each DN container will use up to one core of CPU, so in general you’ll want the number of DNs to equal the number of cores on the system to maximize performance of the service.
For hyperslab selections, the SN container will send a DN request for each chunk accessed. This means that for any selection that spans more than a few chunks, all the DNs will be gainfully employed doing the read or write actions for their set of chunks. By parallelizing these actions HSDS will provide better performance by harnessing all the cores available on the machine.
As an example, we can compare the performance with for HSDS running on varying number of containers. As mentioned in a previous newsletter, in this test case, we retrieve 4000 random columns from a 17520 by 2018392 dataset and get the following runtimes with 4, 8, and 16 DN containers:
- 4 DN: 65.4s
- 8 DN: 35.7s
- 16 DN: 23.4s
In this case performance increased almost linearly with the number of containers. Results for specific applications will depend greatly on the application, HDF5 data layout, and hardware used, so it will be worthwhile to create a similar test for your specific use case.
This architecture enables HSDS to take fully utilize the available CPU, memory, and network bandwidth on a single server. If your needs exceed what can be supplied by one machine, you might be interested on using Kubernetes instead of Docker. Like Docker, Kubernetes is a container management system, but unlike Docker, Kubernetes can be used with a cluster rather than a single machine. Kubernetes is organized a bit differently than Docker though, and this has an impact on how HSDS is deployed, so let’s look at HSDS on Kubernetes next.
In Kubernetes the minimal deployable unit is a “pod”. Each pod contains one or more containers. For HSDS on Kubernetes, each pod has one SN and one DN container. Just as with HSDS on Docker, a client request will get routed to a SN container (on one of the HSDS pods). This SN container will then send requests to either a DN in its own pod, or DN’s in other HSDS pods. Just like with Docker we can take advantage of parallelization, but in this case we can potentially be running on a set of DNs on multiple machines.
The “kubectl get pods” command can be used to list the running pods on a cluster:
$ kubectl get pods` NAME READY STATUS RESTARTS AGE` hsds-755cc5db65-dqc8g 2/2 Running 0 6m`
In this case we have one HSDS pod that has been running for 6 minutes. The READY column shows that this pod has 2 out of 2 (one SN, one DN) containers that are active.
Graphically, the Kubernetes deployment looks like the below diagram.
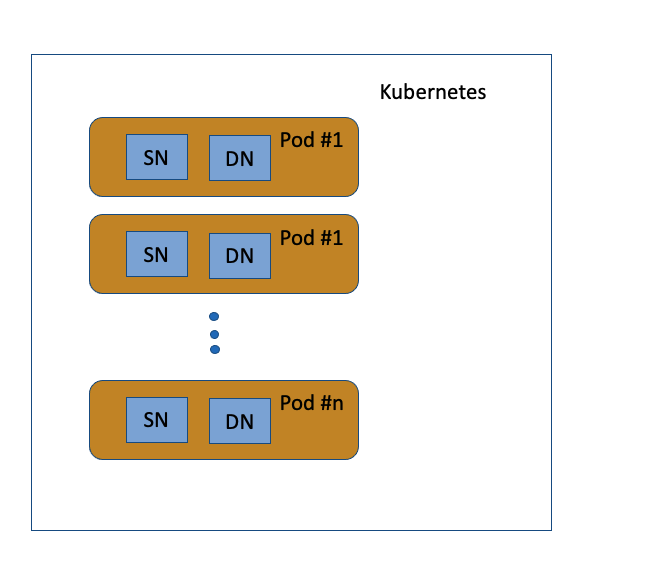 Similar to Docker, Kubernetes using YAML files to specify how the pods will be setup. In the github repo you can find deployment YAMLS, for AWS, Azure, and Posix here. Unlike with Docker deployment YAMLs, the Kubernetes YAML file will require some tweaking to be customized for a specific deployment. See the guide for specific instructions for AWS or Azure.
Similar to Docker, Kubernetes using YAML files to specify how the pods will be setup. In the github repo you can find deployment YAMLS, for AWS, Azure, and Posix here. Unlike with Docker deployment YAMLs, the Kubernetes YAML file will require some tweaking to be customized for a specific deployment. See the guide for specific instructions for AWS or Azure.
Since on Kubernetes HSDS is deployed as a set of pods and each pod contains a SN and DN container, you may wonder how an SN container finds the other DN containers without a head node. It turns out a coordination container is not needed since Kubernetes supplies an API that pods can use to find out if they have sibling pods running on the cluster. For Kubernetes deployments each HSDS container will call the Kubernetes API to get a list of the other HSDS pods running. Other than that, the typical request flow of client to SN to multiple DNs works much like it does with Docker.
One nice aspect of HSDS on Kubernetes is that you can dynamically scale the number of HSDS pods using the “kubectl scale” command. E.g. $kubectl scale --replicas=4 deployments/hsds will increase (or decrease as the case may be) the number of pods to 4. As the number of active pods changes, the existing SN containers will notice the new pods coming online and adjust how they distribute requests to the DN containers. There may be a brief period of service unavailability until all the pods synchronize on the new pod count.
After the above scale command the get pods command will report something like:
$ kubectl get pods` NAME READY STATUS RESTARTS AGE` hsds-755cc5db65-dqc8g 2/2 Running 0 5m` hsds-755cc5db65-fjtdb 2/2 Running 0 1m` hsds-755cc5db65-q58j2 2/2 Running 0 1m` hsds-755cc5db65-txbmb 2/2 Running 0 1m`
What happens if the cluster doesn’t have resources (CPU or memory) to schedule the new pods? In this case, the “STATUS” column will show “Pending” until either more capacity is added (i.e. additional machines are added to the cluster), or additional resources are made available (say another deployment is terminated). In either case as pods transition to the RUNNING state, the SN containers will see them and incorporate the new containers into the DN dispatching logic.
Finally, what about the rangeget container that we saw in the Docker deployment? Since singleton objects don’t fit very well in the Kubernetes architecture, we just do without the rangeget proxy. The lack of the rangeget doesn’t change anything functionally, but could have some impact on performance if HSDS is used to for reading HDF5 files with many small chunks. If that’s the case for your deployment, you may want to rechunk your HDF5 files to use a larger chunk size or just stick with Docker deployments.
As always, let us know if this has raised additional questions, otherwise I hope it’s clarified some things that may have seemed confusing before.